In March of this year, Google DeepMind’s computer program AlphaGo defeated world Go champion Lee Sedol. This was hailed as a great triumph of artificial intelligence and signaled to many the beginning of the new age when machines take over. I believe this is true but the real lesson of AlphaGo’s win is not how great machine learning algorithms are but how suboptimal human Go players are. Experts believed that machines would not be able to defeat humans at Go for a long time because the number of possible games is astronomically large, 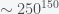 moves, in contrast to chess with a paltry
moves, in contrast to chess with a paltry 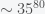 moves. Additionally, unlike chess, it is not clear what is a good position and who is winning during intermediate stages of a game. Thus, any direct enumeration and evaluation of possible next moves as chess computers do, like IBM’s Deep Blue that defeated Gary Kasparov, seemed to be impossible. It was thought that humans had some sort of inimitable intuition to play Go that machines were decades away from emulating. It turns out that this was wrong. It took remarkably little training for AlphaGo to defeat a human. All the algorithms used were fairly standard – supervised and reinforcement backpropagation learning in multi-layer neural networks1. DeepMind just put them together in a clever way and had the (in retrospect appropriate) audacity to try.
moves. Additionally, unlike chess, it is not clear what is a good position and who is winning during intermediate stages of a game. Thus, any direct enumeration and evaluation of possible next moves as chess computers do, like IBM’s Deep Blue that defeated Gary Kasparov, seemed to be impossible. It was thought that humans had some sort of inimitable intuition to play Go that machines were decades away from emulating. It turns out that this was wrong. It took remarkably little training for AlphaGo to defeat a human. All the algorithms used were fairly standard – supervised and reinforcement backpropagation learning in multi-layer neural networks1. DeepMind just put them together in a clever way and had the (in retrospect appropriate) audacity to try.
The take home message of AlphaGo’s success is that humans are very, very far away from being optimal at playing Go. Uncharitably, we simply stink at Go. However, this probably also means that we stink at almost everything we do. Machines are going to take over our jobs not because they are sublimely awesome but because we are stupendously inept. It is like the old joke about two hikers encountering a bear and one starts to put on running shoes. The other hiker says: “Why are you doing that? You can’t outrun a bear.” to which she replies, “I only need to outrun you!” In fact, the more difficult a job seems to be for humans to perform, the easier it will be for a machine to do better. This was noticed a long time ago in AI research and called Moravec’s Paradox. Tasks that require a lot of high level abstract thinking like chess or predicting what movie you will like are easy for computers to do while seemingly trivial tasks that a child can do like folding laundry or getting a cookie out of a jar on an unreachable shelf is really hard. Thus high paying professions in medicine, accounting, finance, and law could be replaced by machines sooner than lower paying ones in lawn care and house cleaning.
There are those who are not worried about a future of mass unemployment because they believe people will just shift to other professions. They point out that a century ago a majority of Americans worked in agriculture and now the sector comprises of less than 2 percent of the population. The jobs that were lost to technology were replaced by ones that didn’t exist before. I think this might be true but in the future not everyone will be a software engineer or a media star or a CEO of her own company of robot employees. The increase in productivity provided by machines ensures this. When the marginal cost of production goes to zero (i.e. cost to make one more item), as it is for software or recorded media now, the whole supply-demand curve is upended. There is infinite supply for any amount of demand so the only way to make money is to increase demand.
The rate-limiting step for demand is the attention span of humans. In a single day, a person can at most attend to a few hundred independent tasks such as thinking, reading, writing, walking, cooking, eating, driving, exercising, or consuming entertainment. I can stream any movie I want now and I only watch at most twenty a year, and almost all of them on long haul flights. My 3 year old can watch the same Wild Kratts episode (great children’s show about animals) ten times in a row without getting bored. Even though everyone could be a video or music star on YouTube, superstars such as Beyoncé and Adele are viewed much more than anyone else. Even with infinite choice, we tend to do what our peers do. Thus, for a population of ten billion people, I doubt there can be more than a few million that can make a decent living as a media star with our current economic model. The same goes for writers. This will also generalize to manufactured goods. Toasters and coffee makers essentially cost nothing compared to three decades ago, and I will only buy one every few years if that. Robots will only make things cheaper and I doubt there will be a billion brands of TV’s or toasters. Most likely, a few companies will dominate the market as they do now. Even, if we could optimistically assume that a tenth of the population could be engaged in producing goods and services necessary for keeping the world functioning that still leaves the rest with little to do.
Even much of what scientists do could eventually be replaced by machines. Biology labs could consist of a principle investigator and robot technicians. Although it seems like science is endless, the amount of new science required for sustaining the modern world could diminish. We could eventually have an understanding of biology sufficient to treat most diseases and injuries and develop truly sustainable energy technologies. In this case, machines could be tasked to keep the modern world up and running with little need of input from us. Science would mostly be devoted to abstract and esoteric concerns.
Thus, I believe the future for humankind is in low productivity occupations – basically a return to pre-industrial endeavors like small plot farming, blacksmithing, carpentry, painting, dancing, and pottery making, with an economic system in place to adequately live off of this labor. Machines can provide us with the necessities of life while we engage in a simulated 18th century world but without the poverty, diseases, and mass famines that made life so harsh back then. We can make candles or bread and sell them to our neighbors for a living wage. We can walk or get in self-driving cars to see live performances of music, drama and dance by local artists. There will be philosophers and poets with their small followings as they have now. However, even when machines can do everything humans can do, there will still be a capacity to sustain as many mathematicians as there are people because mathematics is infinite. As long as P is not NP, theorem proving can never be automated and there will always be unsolved math problems. That is not to say that machines won’t be able to do mathematics. They will. It’s just that they won’t ever be able to do all of it. Thus, the future of work could also be mathematics.
- Silver, D. et al. Mastering the game of Go with deep neural networks and tree search. Nature 529, 484–489 (2016).
 different possible hashes. What makes hashes useful are two properties. The first, as mentioned, is that it is a one-way function and the second is that two different inputs do not give the same hash, called collision avoidance. There have been decades of work on figuring out how to do this and institutions like the US National Institutes of Standards and Technology (NIST) actually publish hash standards like SHA-2.
different possible hashes. What makes hashes useful are two properties. The first, as mentioned, is that it is a one-way function and the second is that two different inputs do not give the same hash, called collision avoidance. There have been decades of work on figuring out how to do this and institutions like the US National Institutes of Standards and Technology (NIST) actually publish hash standards like SHA-2. 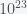 numbers of atoms. How do the stones know what scales they span in the MCU? Do photosynthetic lifeforms get spared since they don’t use many resources? What about fungi? Is the MCU actually a simulated universe where there is a continually updated census of all life? How accurate is the algorithm? Was it perfect? Did it aim for high specificity (i.e. reduce false positives so you only kill lifeforms and not non lifeforms) or high sensitivity (i.e. reduce false negatives and thus don’t miss any lifeforms). I think it probably favours sensitivity over specificity – who cares if a bunch of ammonia molecules accidentally get killed. The find-all-life problem is made much easier by proposition 1 because if all life were material then the only way to detect them would be to look for multiscale correlations between atoms (or find organic molecules if you only care about biochemical life). If each lifeform has a soul then you can simply search for “soulfulness”. The lifeforms were not erased instantly but only after a brief delay. What was happening over this delay. Is magic propagation limited by the speed of light or some other constraint? Or did the computation take time? In Endgame, the Hulk restores all the Thanos erased lifeforms and Tony Stark then snaps away Thanos and all of his allies. Where were the lifeforms after they were erased? In Heaven? In a soul repository somewhere? Is this one of the Nine Realms of the MCU? How do the stones know who is a Thanos ally? The second computation is to then decide which half to extinguish. The movie seems to imply that the choice was random so where did the randomness come from? Do the infinity stones generate random numbers? Do they rely on quantum fluctuations? Finally, in a world with magic, why is there also science? Why does the universe follow the laws of physics sometimes and magic other times. Is magic a finite resource as in Larry Niven’s The Magic Goes Away. So many questions, so few answers.
numbers of atoms. How do the stones know what scales they span in the MCU? Do photosynthetic lifeforms get spared since they don’t use many resources? What about fungi? Is the MCU actually a simulated universe where there is a continually updated census of all life? How accurate is the algorithm? Was it perfect? Did it aim for high specificity (i.e. reduce false positives so you only kill lifeforms and not non lifeforms) or high sensitivity (i.e. reduce false negatives and thus don’t miss any lifeforms). I think it probably favours sensitivity over specificity – who cares if a bunch of ammonia molecules accidentally get killed. The find-all-life problem is made much easier by proposition 1 because if all life were material then the only way to detect them would be to look for multiscale correlations between atoms (or find organic molecules if you only care about biochemical life). If each lifeform has a soul then you can simply search for “soulfulness”. The lifeforms were not erased instantly but only after a brief delay. What was happening over this delay. Is magic propagation limited by the speed of light or some other constraint? Or did the computation take time? In Endgame, the Hulk restores all the Thanos erased lifeforms and Tony Stark then snaps away Thanos and all of his allies. Where were the lifeforms after they were erased? In Heaven? In a soul repository somewhere? Is this one of the Nine Realms of the MCU? How do the stones know who is a Thanos ally? The second computation is to then decide which half to extinguish. The movie seems to imply that the choice was random so where did the randomness come from? Do the infinity stones generate random numbers? Do they rely on quantum fluctuations? Finally, in a world with magic, why is there also science? Why does the universe follow the laws of physics sometimes and magic other times. Is magic a finite resource as in Larry Niven’s The Magic Goes Away. So many questions, so few answers.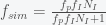
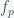 is the fraction of human level civilizations that attain the capability to simulate a human populated civilization,
is the fraction of human level civilizations that attain the capability to simulate a human populated civilization, 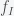 is the fraction of these civilizations interested in running civilization simulations, and
is the fraction of these civilizations interested in running civilization simulations, and  is the average number of simulations running in these interested civilizations. He then argues that if
is the average number of simulations running in these interested civilizations. He then argues that if 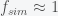 or
or 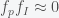 . Musk believes that it is highly likely that
. Musk believes that it is highly likely that  is not small so, ergo, we must be in a simulation.
is not small so, ergo, we must be in a simulation. 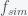 is around 20%.
is around 20%. 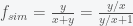
 is the number of non-sim civilizations and
is the number of non-sim civilizations and 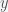 is the number of sim civilizations. (Re-labeling
is the number of sim civilizations. (Re-labeling 

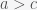 is
is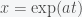


 . However, as long as
. However, as long as  , the first term will dominate.
, the first term will dominate.
 , Drake wrote down his celebrated
, Drake wrote down his celebrated 
 is the rate of star formation,
is the rate of star formation, 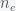 is the average number of planets per star that could support life,
is the average number of planets per star that could support life,  fraction of planets that develop life,
fraction of planets that develop life,  fraction of those planets that develop intelligent life,
fraction of those planets that develop intelligent life,  fraction of civilizations that emit signals, and
fraction of civilizations that emit signals, and  is the length of time civilizations emit signals.
is the length of time civilizations emit signals. . I would say that this is an optimistic estimate. Probabilities get small really quickly when you multiply them together. The probability of single cellular life will be much higher. It is possible that there could be hundred planets in our galaxy that have life but the chance that one of those is within a hundred light years will again be very low. However, I do think it is a worthwhile exercise to look for extracellular life, especially for oxygen or other life emitting gases in the atmosphere of exoplanets. It could tell us a lot about biology on earth.
. I would say that this is an optimistic estimate. Probabilities get small really quickly when you multiply them together. The probability of single cellular life will be much higher. It is possible that there could be hundred planets in our galaxy that have life but the chance that one of those is within a hundred light years will again be very low. However, I do think it is a worthwhile exercise to look for extracellular life, especially for oxygen or other life emitting gases in the atmosphere of exoplanets. It could tell us a lot about biology on earth.
