Although cryptocurrencies have been mainstream for quite a while, I still think the popular press has not done a great job explaining the details of how they work. There are several ideas behind a cryptocurrency like Bitcoin but the main one is the concept of a cryptographic hash. In simple terms, a hash is a way to transform an input sequence of characters (i.e. a string) into an output string such that it is hard to recreate the input string from the output string. A transformation with this property is called a one-way function. It is a machine where you get an output from an input but you can’t get the input from the output and there does not exist any other machine that can get the input from the output. A hash is a one-way function where the output has a standard form, e.g. 64 characters long. So if each character is a bit, e.g. 0 or 1, then there are 
Hashes are an important part of your life. If a company is responsible, then only the hash of your password is stored on their servers, and when you type your password into a website, it goes through the hashing function and the hash is checked against the stored version. That way, if there is security breach, only the hash list is stolen. If the company is very responsible, then your name and all of your information is also only stored in hash form. Part of the problem with past security breaches is that the companies stored actual information instead of hashed information. However, if you use the same password on different websites then the hash would be same if the same standard was used. Some really careful companies will “salt” your password by adding a random string to it (that is hopefullly stored separately) before hashing. Or they will rehash your hash with salt. If you had a perfect hash, then the only way to break it would be to guess different inputs and see if it matches the desired output. The so-called complex math problem that Bitcoin solves before validating a transaction (and getting a reward) is finding a hash with a certain property but more on this later.
Now, one of the problems with hashing is that you need to deal with inputs of various sizes but you want the output to have a single uniform size. So even though a hash could have enough information capacity (i.e. entropy) to encode all of the world’s information ten times over, it is computationally inconvenient to just feed the complete text of Hamlet directly into a single one-way function. This is where the concept of a Merkle tree becomes important. You start with some one-way function that takes inputs of some fixed length and it scrambles the characters in some way that is not easily reversible. If the input string is too short then you just add extra characters (called padding) but if it is too long you need to do something else. The way a Merkle tree works is to break the text into chunks of uniform size. It then hashes the first chunk, adds that to the next chunk, hash the result and repeat until you have included all the chunks. This repeated recursive hashing is the secret sauce of crypto-currencies.
Bitcoin tried to create a completely decentralized digital currency that could be secure and trusted. For a regular currency like the US dollar, the thing you are most concerned about is that the dollar you receive is not counterfeit. The way that problem is solved is to make the manufacturing process of dollar bills very difficult to reproduce. So the dollar uses special paper with special marks and threads and special fonts and special ink. There are laws against making photocopiers with a higher resolution than the smallest print on a US bill to safeguard against counterfeiting. A problem with digital currencies is that you need to prevent double spending. The way this is historically solved is to have all transactions validated by a central authority.
Bitcoin solves these problems in a decentralized system by using a public ledger, called a blockchain that is time stamped, immutable and verifiable. The block chain keeps track of every Bitcoin transaction. So if you wanted to transfer one Bitcoin to someone else then the blockchain would show that your private Bitcoin ID has one less Bitcoin and the ID of the person you transferred to would have one extra Bitcoin. It is called a blockchain because each transaction (or set of transactions) is recorded into a block, the blocks are sequential, and each block contains a hash of the previous block. To validate a transaction you would need to validate each transaction leading up to the last block to validate that the hash on each block is correct. Thus the blockchain is a Merkle tree ledger where each entry is time stamped, immutable, and verifiable. If you want to change a block you need to change all the blocks before it.
However, the blockchain is not decentralized on its own. How do you prevent two blocks with two different hashes? The way to achieve that goal is to make the hash used in each block have a special form that is hard to find. This underlies the concept of “proof of work”. Bitcoin uses a hash called SHA-256 which consists of a hexadecimal string of 64 characters (i.e. a base 16 number, usually with characters consisting of the digits 0-9 plus letters a-f). Before each block gets added to the chain, it must have a hash that has a set number of zeros at the front. In order to do this, you need to add some random numbers to the block or rearrange it so that the hash changes. This is what Bitcoin miners do. They try different variations of the block until they get a hash that has a certain number of zeros in front and then they race to see who gets it first. The more zeros you need the more guesses you need and thus the harder the computation. If it’s just one zero then one in 16 hashes will have that property and thus on average 16 tries will get you the hash and the right to add to the blockchain. Each time you require an additional zero, the number of possibilities decreases by a factor of 16 so it is 16 times harder to find one. Bitcoin wants to keep the computation time around 15 minutes so as computation speed increases it just adds another zero. The result is an endless arms race. The faster the computers get the harder the hash is to find. The incentive for miners to be fast is that they get some Bitcoins if they are successful in being the first to find a desired hash and earning the right to add a block to the chain.
The actual details for how this works is pretty complicated. All the miners (or Bitcoin nodes) must validate that the proposed block is correct and then they all must agree to add that to the chain. The way it works in a decentralized way is that the code is written so that a node will follow the longest chain. In principle, this is secure because a dishonest miner who wants to change a previous block must change all blocks following it and thus as long as there are more honest miners than dishonest ones, the dishonest ones can never catch up. However, there are issues when two miners simultaneously come up with a hash and they can’t agree on which to follow. This is called a fork and has happened at least once I believe. This gets fixed eventually because honest miners will adopt the longest chain and the chain with the most adherents will grow the fastest. However, in reality there are only a small number of miners that regularly add to the chain so we’re at a point now where a dishonest actor could possibly dominate the honest ones and change the blockchain. Proof of work is also not the only way to add to a blockchain. There are several creative ideas to make it less wasteful or even make all that computation useful and I may write about them in the future. I’m somewhat skeptical about the long term viability of Bitcoin per se but I think the concepts of the blockchain are revolutionary and here to stay.
2021-06-21: some typos fixed and clarifying text added.
 , where
, where  is the universal gravitational constant,
is the universal gravitational constant, 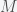 is the mass of the earth,
is the mass of the earth, 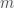 is the mass of the object and
is the mass of the object and  is the distance between the objects. By a very deep property of the universe, the mass in Newton’s law of gravitation is the exact same mass as that in Newton’s second law, called inertial mass. So that means if we let
is the distance between the objects. By a very deep property of the universe, the mass in Newton’s law of gravitation is the exact same mass as that in Newton’s second law, called inertial mass. So that means if we let  , then we get
, then we get  , and
, and 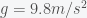 is the gravitational acceleration constant if we set
is the gravitational acceleration constant if we set 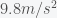 . If gravitational mass and inertial mass were not the same, then objects of different masses would not fall with the same acceleration. Many people know that Galileo showed this fact in his famous experiment where he dropped a big and small object from the Leaning Tower of Pisa. However, many probably also cannot explain why including my grade 7 (or was it 8) science teacher who thought it was because the earth’s mass was much bigger than the two objects so the difference was not noticeable. The equivalence of gravitational and inertial mass was what led Einstein to his General Theory of Relativity.
. If gravitational mass and inertial mass were not the same, then objects of different masses would not fall with the same acceleration. Many people know that Galileo showed this fact in his famous experiment where he dropped a big and small object from the Leaning Tower of Pisa. However, many probably also cannot explain why including my grade 7 (or was it 8) science teacher who thought it was because the earth’s mass was much bigger than the two objects so the difference was not noticeable. The equivalence of gravitational and inertial mass was what led Einstein to his General Theory of Relativity.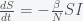
 (SIR model)
(SIR model) is the total number of people in the population of interest. Here,
is the total number of people in the population of interest. Here, 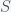 and
and 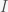 are in units of number of people. The left hand sides of these equations are derivatives with respect to time, or rates. They have dimensions or units of people per unit time, say day. From this we can infer that
are in units of number of people. The left hand sides of these equations are derivatives with respect to time, or rates. They have dimensions or units of people per unit time, say day. From this we can infer that  and
and 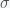 must have units of inverse day (per day) since
must have units of inverse day (per day) since 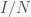 . If there was one infected person in a population of a hundred, then if you were to interact completely randomly with everyone then the chance you would run into an infected person is 1/100. Actually, it would be 1/99 but in a large population, the one becomes insignificant and you can round up. Right away, we can see a problem with this assumption. I interact regularly with perhaps a few hundred people per week or month but the chance of me meeting a person that had just come from Australia in a typical week is extremely low. Thus, it is not at all clear what we should use for
. If there was one infected person in a population of a hundred, then if you were to interact completely randomly with everyone then the chance you would run into an infected person is 1/100. Actually, it would be 1/99 but in a large population, the one becomes insignificant and you can round up. Right away, we can see a problem with this assumption. I interact regularly with perhaps a few hundred people per week or month but the chance of me meeting a person that had just come from Australia in a typical week is extremely low. Thus, it is not at all clear what we should use for 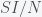 . The rate of change of
. The rate of change of  . These terms all have units of person per day. Once you understand the basic principles of constructing differential equations, you can model anything, which is what I like to do. For example, I modeled the temperature dynamics of my house this winter and used it to optimize my thermostat settings. In a post from a long time ago, I used it to model how best to boil water.
. These terms all have units of person per day. Once you understand the basic principles of constructing differential equations, you can model anything, which is what I like to do. For example, I modeled the temperature dynamics of my house this winter and used it to optimize my thermostat settings. In a post from a long time ago, I used it to model how best to boil water. is some nice function like
is some nice function like  or
or  . However, you can solve them numerically on a computer or infer properties of the dynamics directly without actually solving them. For example, if
. However, you can solve them numerically on a computer or infer properties of the dynamics directly without actually solving them. For example, if 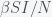 is initially greater than
is initially greater than  is always negative (rate of change is negative), it will decrease in time. As
is always negative (rate of change is negative), it will decrease in time. As 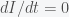 . This is a stationary point of
. This is a stationary point of 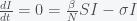 (Stationary condition)
(Stationary condition) or
or  . The
. The 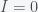 point is not a peak but just reflects the fact that there is no epidemic if there are no infections. The other condition gives the peak:
point is not a peak but just reflects the fact that there is no epidemic if there are no infections. The other condition gives the peak: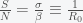
 is the now-famous R naught or initial reproduction number. It is the average number of people infected by a single person since
is the now-famous R naught or initial reproduction number. It is the average number of people infected by a single person since  then the pandemic will begin to decline. This is usually expressed as the fraction of those infected and no longer susceptible,
then the pandemic will begin to decline. This is usually expressed as the fraction of those infected and no longer susceptible,  . The 70% number you have heard is because
. The 70% number you have heard is because  is approximately 70% for
is approximately 70% for 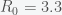 , the presumed value for Covid-19.
, the presumed value for Covid-19.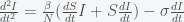
 at the peak, the curvature is
at the peak, the curvature is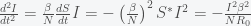
 is small compared to
is small compared to  . However, this would also mean we are already at the herd immunity threshold, which our paper and recent anti-body surveys predict to be unlikely given what we know about
. However, this would also mean we are already at the herd immunity threshold, which our paper and recent anti-body surveys predict to be unlikely given what we know about 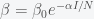 ,where
,where  is the initial infectivity rate, but any decreasing function will do. When
is the initial infectivity rate, but any decreasing function will do. When 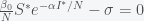
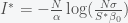
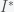 , then
, then 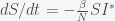 , which has solution
, which has solution (S)
(S)
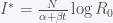
 is given by equation (S). Substituting this into the (Stationary Condition) above then gives
is given by equation (S). Substituting this into the (Stationary Condition) above then gives  or
or
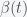 is creeping upwards back to it’s original value.
is creeping upwards back to it’s original value. days! In other words, the pandemic will keep circling the world forever since over that time span, babies will be born and grow up. Most likely, it will become less virulent and will just join the panoply of diseases we currently live with like the various varieties of the common cold (which are also corona viruses) and the flu.
days! In other words, the pandemic will keep circling the world forever since over that time span, babies will be born and grow up. Most likely, it will become less virulent and will just join the panoply of diseases we currently live with like the various varieties of the common cold (which are also corona viruses) and the flu. and treat them as some abstract quantity. In fact, I often just look at differential equations of the form
and treat them as some abstract quantity. In fact, I often just look at differential equations of the form
 is a solution, where
is a solution, where  is any constant number, because the derivative of an exponential function is an exponential function. One confusing aspect of discussing exponential growth with lay people is that the above equation is called a linear differential equation and often mathematicians or physicists will simply say the dynamics are linear or even the growth is linear, although what we really mean is that the describing equation is a linear differential equation, which has exponential growth or exponential decay if
is any constant number, because the derivative of an exponential function is an exponential function. One confusing aspect of discussing exponential growth with lay people is that the above equation is called a linear differential equation and often mathematicians or physicists will simply say the dynamics are linear or even the growth is linear, although what we really mean is that the describing equation is a linear differential equation, which has exponential growth or exponential decay if 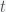 represent time (say days) then
represent time (say days) then  actually means is that every day
actually means is that every day  , e.g. number of people with covid-19, is increasing by a factor of
, e.g. number of people with covid-19, is increasing by a factor of  , which is about 2.718. Now, while this is the most convenient number for mathematical manipulation, it is definitely not the most convenient number for intuition. A common alternative is to use 2 as the base of the exponent, rather than
, which is about 2.718. Now, while this is the most convenient number for mathematical manipulation, it is definitely not the most convenient number for intuition. A common alternative is to use 2 as the base of the exponent, rather than 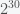 , which is only 10 million or so. But on day 31 you have 20 million and day 32 you have 40 million. It’s growing really fast.
, which is only 10 million or so. But on day 31 you have 20 million and day 32 you have 40 million. It’s growing really fast.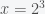 then
then  (i.e. the log of x in base 2 is 3). Log just gives you the power of an exponential (in that base). So the only difference between using base 2 versus base 10 is the rate of growth. For example
(i.e. the log of x in base 2 is 3). Log just gives you the power of an exponential (in that base). So the only difference between using base 2 versus base 10 is the rate of growth. For example  , where
, where  . So an exponential process that is doubling every day is increasing by a factor of ten every 3.3 days.
. So an exponential process that is doubling every day is increasing by a factor of ten every 3.3 days. , is the total genetic variance divided by the phenotypic variance. Narrow sense heritability
, is the total genetic variance divided by the phenotypic variance. Narrow sense heritability  is the linear or additive genetic variance divided by the phenotypic variance. A linear regression of the standardized trait of the children against the average of the standardized trait of the parents is an estimate of the narrow sense heritability. It captures the linear part while the broad sense heritability includes the linear and nonlinear contributions, which include dominance and gene-gene effects (epistasis). To estimate (narrow-sense) heritability from twins, Polderman et al. used what is called Falconer’s formula and took twice the difference in the correlation of a trait between identical (monozygotic) and fraternal (dizygotic) twins (
is the linear or additive genetic variance divided by the phenotypic variance. A linear regression of the standardized trait of the children against the average of the standardized trait of the parents is an estimate of the narrow sense heritability. It captures the linear part while the broad sense heritability includes the linear and nonlinear contributions, which include dominance and gene-gene effects (epistasis). To estimate (narrow-sense) heritability from twins, Polderman et al. used what is called Falconer’s formula and took twice the difference in the correlation of a trait between identical (monozygotic) and fraternal (dizygotic) twins (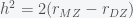 ). The idea being that the any difference between identical twins must be environmental (nongenetic), while the difference between dyzgotic twins is half genetic and environmental, so the difference between the two is half genetic. They also used another Falconer formula to estimate the shared environmental variance, which is
). The idea being that the any difference between identical twins must be environmental (nongenetic), while the difference between dyzgotic twins is half genetic and environmental, so the difference between the two is half genetic. They also used another Falconer formula to estimate the shared environmental variance, which is  , since this “cancels out” the genetic part. Their paper then boiled down to doing a meta-analysis of
, since this “cancels out” the genetic part. Their paper then boiled down to doing a meta-analysis of 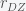 and
and  . Meta-analysis is a nuanced topic but it boils down to weighting results from different studies by some estimate of how large the errors are. They used the DerSimonian-Laird random-effects approach, which is implemented in R. The Falconer formulas estimate the narrow sense heritability but many of the previous studies were interested in nonadditive genetic effects as well. Typically, what they did was to use either an ACE (Additive, common environmental, environmental) or an ADE (Additive, dominance, environmental) model. They decided on which model to use by looking at the sign of
. Meta-analysis is a nuanced topic but it boils down to weighting results from different studies by some estimate of how large the errors are. They used the DerSimonian-Laird random-effects approach, which is implemented in R. The Falconer formulas estimate the narrow sense heritability but many of the previous studies were interested in nonadditive genetic effects as well. Typically, what they did was to use either an ACE (Additive, common environmental, environmental) or an ADE (Additive, dominance, environmental) model. They decided on which model to use by looking at the sign of 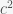 . If it is positive then they used ACE and if it is negative they used ADE. Polderman et al. showed that this decision algorithm biases the heritability estimate downward.
. If it is positive then they used ACE and if it is negative they used ADE. Polderman et al. showed that this decision algorithm biases the heritability estimate downward.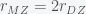 and they found that this was observed in 69% of the traits. Of the top 20 traits, 8 traits showed nonadditivity and these mostly related to behavioral and cognitive functions. Of these eight, 7 showed that the correlation between monozygotic twins was smaller than twice that of dizygotic twins, which implies that nonlinear genetic effects tend to work against each other. This makes sense to me since it would seem that as you start to accumulate additive variants that increase a phenotype you will start to hit rate limiting effects that will tend to dampen these effects. In other words, it seems plausible that the major nonlinearity in genetics is a saturation effect.
and they found that this was observed in 69% of the traits. Of the top 20 traits, 8 traits showed nonadditivity and these mostly related to behavioral and cognitive functions. Of these eight, 7 showed that the correlation between monozygotic twins was smaller than twice that of dizygotic twins, which implies that nonlinear genetic effects tend to work against each other. This makes sense to me since it would seem that as you start to accumulate additive variants that increase a phenotype you will start to hit rate limiting effects that will tend to dampen these effects. In other words, it seems plausible that the major nonlinearity in genetics is a saturation effect. would be uniform or at least symmetric about 0.5. This sounds plausible but as I have asserted many times – biology is the result of an exponential amplification of exponentially unlikely events. Traits that are heritable are by definition those that have variation across the population. Some traits, like the number of limbs, have no variance but are entirely genetic. Other traits, like your favourite sports team, are highly variable but not genetic even though there is a high probability that your favourite team will be the same as your parent’s or sibling’s favourite team. Traits that are highly heritable include height and cognitive function. Personality on the other hand, is not highly heritable. One of the biggest puzzles in population genetics is why there is any variability in a trait to start with. Natural selection prunes out variation exponentially fast so if any gene is selected for, it should be fixed very quickly. Hence, it seems equally plausible that traits with high variability would have low heritability. The studied traits were also biased towards mental function and different domains have different heritabilities. Thus, if the traits were sampled differently, the averaged heritability could easily deviate from 0.5. Thus, I think the null hypothesis should be that the
would be uniform or at least symmetric about 0.5. This sounds plausible but as I have asserted many times – biology is the result of an exponential amplification of exponentially unlikely events. Traits that are heritable are by definition those that have variation across the population. Some traits, like the number of limbs, have no variance but are entirely genetic. Other traits, like your favourite sports team, are highly variable but not genetic even though there is a high probability that your favourite team will be the same as your parent’s or sibling’s favourite team. Traits that are highly heritable include height and cognitive function. Personality on the other hand, is not highly heritable. One of the biggest puzzles in population genetics is why there is any variability in a trait to start with. Natural selection prunes out variation exponentially fast so if any gene is selected for, it should be fixed very quickly. Hence, it seems equally plausible that traits with high variability would have low heritability. The studied traits were also biased towards mental function and different domains have different heritabilities. Thus, if the traits were sampled differently, the averaged heritability could easily deviate from 0.5. Thus, I think the null hypothesis should be that the 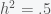 value is a coincidence but I’m open to a deeper explanation.
value is a coincidence but I’m open to a deeper explanation. on some domain
on some domain ![[x_{\min},x_{\max}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B%5Cmin%7D%2Cx_%7B%5Cmax%7D%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) and you want to generate a set of numbers that follows this probability law. This is actually very simple to do although those new to the field may not know how. Generally, any programming language or environment has a built-in random number generator for real numbers (up to machine precision) between 0 and 1. Thus, what you want to do is to find a way to transform these random numbers, which are uniformly distributed on the domain
and you want to generate a set of numbers that follows this probability law. This is actually very simple to do although those new to the field may not know how. Generally, any programming language or environment has a built-in random number generator for real numbers (up to machine precision) between 0 and 1. Thus, what you want to do is to find a way to transform these random numbers, which are uniformly distributed on the domain ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) to the random numbers you want. The first thing to notice is that the cumulative distribution function (CDF) for your PDF,
to the random numbers you want. The first thing to notice is that the cumulative distribution function (CDF) for your PDF,  is a function that ranges over the interval
is a function that ranges over the interval  . The numbers you get out satisfy your distribution (i.e.
. The numbers you get out satisfy your distribution (i.e.  ).
). then you can just plug the random numbers directly into your function, otherwise you have to do a little more work. If you don’t have a closed form expression for the CDF then you can just solve the equation
then you can just plug the random numbers directly into your function, otherwise you have to do a little more work. If you don’t have a closed form expression for the CDF then you can just solve the equation  for
for ![v[j]=\sum_{i=0}^j \rho(ih+x_{\min}) h](https://s0.wp.com/latex.php?latex=v%5Bj%5D%3D%5Csum_%7Bi%3D0%7D%5Ej+%5Crho%28ih%2Bx_%7B%5Cmin%7D%29+h&bg=f5f6f7&fg=444444&s=0&c=20201002) , for some discretization parameter
, for some discretization parameter  such that
such that 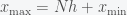 . If the PDF is defined on the entire real line then you’ll have to decide on what you want the minimum
. If the PDF is defined on the entire real line then you’ll have to decide on what you want the minimum 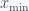 and maximum (through
and maximum (through 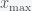 to be. If the distribution has thin tails, then you just need to go out until the probability is smaller than your desired error tolerance. You then find the index
to be. If the distribution has thin tails, then you just need to go out until the probability is smaller than your desired error tolerance. You then find the index  such that
such that ![v[j]](https://s0.wp.com/latex.php?latex=v%5Bj%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) is closest to
is closest to  .
. , to the desired PDF for
, to the desired PDF for  . Thus,
. Thus,  or
or 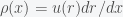 . Now,
. Now,  is the PDF of
is the PDF of 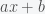 to some data. See here for the original post on
to some data. See here for the original post on 
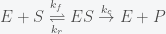
 (1)
(1)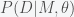 is just the parameter dependent likelihood function we used to find the posterior probabilities for the parameters of the model.
is just the parameter dependent likelihood function we used to find the posterior probabilities for the parameters of the model. (2)
(2)![\frac{d}{d\beta}\ln Z(\beta)=\frac{\int d\theta \ln[P(D |\theta,M)] P(D | \theta, M)^\beta P(\theta|M)}{\int d\theta \ P(D | \theta, M)^\beta P(\theta | M)}](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bd%7D%7Bd%5Cbeta%7D%5Cln+Z%28%5Cbeta%29%3D%5Cfrac%7B%5Cint+d%5Ctheta+%5Cln%5BP%28D+%7C%5Ctheta%2CM%29%5D+P%28D+%7C+%5Ctheta%2C+M%29%5E%5Cbeta+P%28%5Ctheta%7CM%29%7D%7B%5Cint+d%5Ctheta+%5C+P%28D+%7C+%5Ctheta%2C+M%29%5E%5Cbeta+P%28%5Ctheta+%7C+M%29%7D&bg=f5f6f7&fg=444444&s=0&c=20201002) (3)
(3)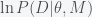 . However, if we assume that the MCMC has reached stationarity then we can replace the ensemble average with a time average
. However, if we assume that the MCMC has reached stationarity then we can replace the ensemble average with a time average 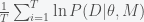 . Integrating (3) over
. Integrating (3) over 
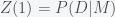 , which is what we want to compute and
, which is what we want to compute and  .
. as the likelihood in the standard MCMC) and then integrate the log likelihoods
as the likelihood in the standard MCMC) and then integrate the log likelihoods  over
over 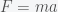 and then there is gravitational mass which is like the “charge” of gravity. The more gravitational mass you have the stronger the gravitational force. Although they didn’t need to be, these two masses happen to be the same. The equivalence of inertial and gravitational mass is one of the deepest facts of the universe and is the reason that all objects fall at the same rate. Galileo’s apocryphal Leaning Tower of Pisa experiment was a proof that the two masses are the same. You can see this by noting that the gravitational force is given by
and then there is gravitational mass which is like the “charge” of gravity. The more gravitational mass you have the stronger the gravitational force. Although they didn’t need to be, these two masses happen to be the same. The equivalence of inertial and gravitational mass is one of the deepest facts of the universe and is the reason that all objects fall at the same rate. Galileo’s apocryphal Leaning Tower of Pisa experiment was a proof that the two masses are the same. You can see this by noting that the gravitational force is given by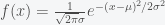
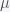 , which coincides with the peak of the bell, and the standard deviation
, which coincides with the peak of the bell, and the standard deviation 