Contemporary American composer Augusta Read Thomas’s Bassoon Concertino (2013) played by the Danish Chamber Players.
Month: August 2015
Brave New World
Read Steve Hsu’s Nautilus article on Super-Intelligence. If so-called IQ-related genetic variants are truly additive then his estimates are probably correct. His postulated being could possibly understand the fine details of any topic in less than a day or shorter. Instead of taking several years to learn enough differential geometry to develop Einstein’s General Relativity (which is what it took for Einstein), a super-intelligence could perhaps do it in an afternoon or during a coffee break. Personally, I believe that nothing is free and that there will always be tradeoffs. I’m not sure what the cost of super-intelligence will be but there will likely be something. Variability in a population is always good for the population although not so great for each individual. An effective way to make a species go extinct is to remove variability. If pests had no genetic variability then it would be a simple matter to eliminate them with some toxin. Perhaps, humans will be able to innovate fast enough to buffer them against environmental changes. Maybe cognitive variability can compensate for genetic variability. I really don’t know.
Selection of the week
The Mozart Clarinet Quintet in A Major, K581, played by the Hagen Quartet with clarinetist Sabine Meyer.
Selection of the week
Perhaps the greatest violinist of the twentieth century and maybe of all time, Jascha Heifetz, playing Melodie from Orphée et Eurydice by Christoph Willibald Gluck. Although the YouTube notes says it was transcribed by Heifetz, I believe this is a version transcribed by Fritz Kreisler.
Guest Post: On Proving Too Much in Scientific Data Analysis
I asked Rick Gerkin to write a summary of his recent eLife paper commenting on a much hyped Science paper on how many odours we can discriminate.
On Proving Too Much in Scientific Data Analysis
by Richard C. Gerkin
First off, thank you to Carson for inviting me to write about this topic.
Last year, Science published a paper by a group at Rockefeller University claiming that humans can discriminate at least a trillion smells. This was remarkable and exciting because, as the authors noted, there are far fewer than a trillion mutually discriminable colors or pure tones, and yet olfaction has been commonly believed to be much duller than vision or audition, at least in humans. Could it in fact be much sharper than the other senses?
After the paper came out in Science, two rebuttals were published in eLife. The first was by Markus Meister, an olfaction and vision researcher and computational neuroscientist at Cal Tech. My colleague Jason Castro and I had a separate rebuttal. The original authors have also posted a re-rebuttal of our two papers (mostly of Meister’s paper), which has not yet been peer reviewed. Here I’ll discuss the source of the original claim, and the logical underpinnings of the counterclaims that Meister, Castro, and I have made.
How did the original authors support their claim in the Science paper? Proving this claim by brute force would have been impractical, so the authors selected a representative set of 128 odorous molecules and then tested a few hundred random 30-component mixtures of those molecules. Since many mixture stimuli can be constructed in this way but only a small fraction can be practically tested, they tried to extrapolate their experimental results to the larger space of possible mixtures. They relied on a statistical transformation of the data, followed by a theorem from the mathematics of error-correcting codes, to estimate — from the data they collected — a lower bound on the actual number of discriminable olfactory stimuli.
The two rebuttals in eLife are mostly distinct from one another but have a common thread: both effectively identify the Science paper’s analysis framework with the logical fallacy of `proving too much‘, which can be thought of as a form of reductio ad absurdum. An argument `proves too much’ when it (or an argument of parallel construction) can prove things that are known to be false. For example, the 11th century theologian St. Anselm’s ontological argument [ed note: see previous post] for the existence of god states (in abbreviated form): “God is the greatest possible being. A being that exists is greater than one that doesn’t. If God does not exist, we can conceive of an even greater being, that is one that does exist. Therefore God exists”. But this proves too much because the same argument can be used to prove the existence of the greatest island, the greatest donut, etc., by making arguments of parallel construction about those hypothetical items, e.g. “The Lost Island is the greatest possible island…” as shown by Anselm’s contemporary Gaunilo of Marmoutiers. One could investigate further to identify more specific errors in logic in Anselm’s argument, but this can be tricky and time-consuming. Philosophers have spent centuries doing just this, with varying levels of success. But simply showing that the argument proves too much is sufficient to at least call the conclusion into question. This makes `proves too much’ a rhetorically powerful approach. In the context of a scientific rebuttal, leading with a demonstration that this fallacy has occurred piques enough reader interest to justify a dissection of more specific technical errors. Both eLife rebuttals use this approach, first showing that the analysis framework proves too much, and then exploring the source(s) of the error in greater detail.
How does one show that a particular detailed mathematical analysis `proves too much’ about experimental data? Let me reduce the analysis in the Science paper to the essentials, and abstract away all the other mathematical details. The most basic claim in that paper is based upon what I will call `the analysis framework’:
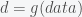
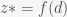
The authors did three basic things. First, they extracted a critical parameter 
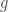
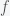

1) How does the quantity
2) What implicit assumptions does
3) Is the stated inequality — which says that any number
What are the rebuttals about? Meister’s paper rejects the equation 2 on the grounds that 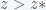
In Meister’s paper, he shows that the analysis framework proves too much by using simulations of simple models, using either synthetic data or the actual data from the original paper. These simulations show that the original analysis framework can generate all sorts of values for 
Meister then explores the reason the equations are flawed, and identifies the flaw in
Meister argues that 
In my paper with Castro, we show that the original paper proves too much in a different way. We show that very similar datasets (differing only in the number of subjects, the number of experiments, or the number of molecules) or very similar analytical choices (differing only in the statistical significance criterion or discriminability thresholds used) produce vastly different estimates for 
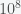

We then showed the technical source of the error, which is a very steep dependence of 



Now suppose some researcher went a step further and said, “If there are 
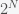
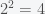
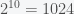

Any particular claim about the number of inflammation phenotypes from this approach would be arbitrary, incredibly sensitive to the significance threshold, and not worth considering seriously. One could obtain nearly any number of inflammation phenotypes one wanted, just by setting the significance threshold accordingly (and all of those thresholds, in different contexts, are considered reasonable in experimental science).
But this is essentially what the function
2015-08-14: typos fixed
A calorie is a calorie (more or less) after all
Just out in Cell Metabolism is Kevin Hall’s most recent paper that shows that low carb diets have no metabolic advantage over a low fat diet. In the experiment, a group of 19 individuals spent 22 days in total in a metabolic ward where their diet was completely specified and metabolic parameters were carefully measured. The individuals were put on both isocaloric carbohydrate reduced diets and fat reduced diets where the order of the diets was randomized over subjects. The short version of the result was that those on the fat reduced diets had more fat loss than the carbohydrate reduced diet although the cumulative difference was small. The body composition changes and metabolic parameters are also matched by the detailed NIDDK body weight model. You most certainly do not lose more fat on a low carb diet.
The results do show that a calorie is not exactly a calorie meaning that the macronutrient composition of the food you eat can matter although over long time periods the body weight model does show that macronutrient differences will always be small. Ultimately, if you want to lose fat, you should eat less and exercise more (in that order). It’s your choice in how you want to reduce your calories. If you like to go low carb then by all means do that. If you like low fat then do that too. You’ll lose weight and fat on both diets. The key is to stick to your diet.
This experimental result is in direct contradiction to the argument of low carb aficionados like Gary Taubes who claim that reducing carbs are particularly beneficial for losing weight and vice versa. Their reasoning is that carbs induce insulin, which suppresses lypolysis from fat cells. Hence, if you ate carbs all the time, your fat would get locked away in adipocytes forever and you would become very fat. However, the problem with this type of reasoning is that it doesn’t account for the fact that no one eats for 24 hours each day. Even the most ardent grazer must sleep at some point and during that time insulin will fall and fat can be released from fat cells. Thus, what you need to do is to account for the net flux of fat over the entire 24 hour cycle and possibly even longer since your body will also adapt to whatever your diet happens to be. When you do that it turns out that you will lose more fat if you reduce fat.
Now this was only for a diet of 6 days but experiments, funded by Gary Taubes’s organization, for longer time scales comparing the two diets have been completed and will be published in the near future. I’ll summarize the results when they come out. I can’t say what the preliminary results are except to remind you that the model has held up pretty well in past.
What is wrong with obesity research
This paper in Nature Communications 14-3-3ζ Coordinates Adipogenesis of Visceral Fat has garnered some attention in the popular press. It is also a perfect example of what is wrong with the way modern obesity research is conducted and reported. This paper finds a protein that regulates adipogenesis or fat cell production. I haven’t gone into details of the results but let’s just assume that it is correct. The problem is that the authors and the press then make the statement that this provides a possible drug target for obesity. Why is this a problem? Well consider the analogy with a car. The gas tank represents the adipocytes, – it is the store of energy. Now, you find a “gene” that shrinks the gas tank and then publish in Nature Automobiles and the press release states that that you have found a potential treatment for car obesity. If it is really true that the car (mouse) still takes in the same amount of petrol (food) as before, then where did this excess energy go? The laws of thermodynamics must still hold. The only possibilities are that your gas mileage went down (energy expenditure increased) or the energy is being stored in some other auxiliary gas tank (liver?). A confounding problem is that rodents have very high metabolic rates compared to humans. They must eat a significant fraction of their body weight each day just to stay alive. Deprive a mouse or rat of food for a few days and it will expire. The amount of energy going into fat storage per day is a small amount by comparison. It is difficult to measure food intake precisely enough to resolve whether or not two rats are eating the same thing and most molecular biology labs are not equipped to make these precise measurements nor understand that they are necessary. One rat needs to only eat more by a small amount to gain more weight. If two cars (mice) grow at different weights then the only two possible explanations is that they have different energy expenditures or they are eating different amounts. Targeting the gas tank (adipocytes) simply does not make sense as a treatment of obesity. It might be interesting from the point of view of understanding development or even cancer but not weight gain. I have argued in the past that if you find that you have too much gas in the car then the most logical thing to do is to put less gas in the car, not to drive faster so you burn up the gas. If you are really interested in understanding obesity, you should try to understand appetite and satiety because that has the highest leverage for affecting body weight.
Selection of the week
Here is Chinese pianist Lang Lang playing Franz Schubert’s Serenade. I think this is probably what a Franz Liszt concert was like to a 19th century concert goer.

{kind=link}