If I had to compress everything that ails us today into one word it would be correlations. Basically, everything bad that has happened recently from the financial crisis to political gridlock is due to undesired correlations. That is not to say that all correlations are bad. Obviously, a system without any correlations is simply noise. You would certainly want the activity on an assembly line in a factory to be correlated. Useful correlations are usually serial in nature like an invention leads to a new company. Bad correlations are mostly parallel like all the members in Congress voting exclusively along party lines, which reduces an assembly with hundreds of people into just two. A recession is caused when everyone in the economy suddenly decides to decrease spending all at once. In a healthy economy, people would be uncorrelated so some would spend more when others spend less and the aggregate demand would be about constant. When people’s spending habits are tightly correlated and everyone decides to save more at the same time then there would be less demand for goods and services in the economy so companies must lay people off resulting in even less demand leading to a vicious cycle.
The financial crisis that triggered the recession was due to the collapse of the housing bubble, another unwanted correlated event. This was exacerbated by collateralized debt obligations (CDOs), which are financial instruments that were doomed by unwanted correlations. In case you haven’t followed the crisis, here’s a simple explanation. Say you have a set of loans where you think the default rate is 50%. Hence, given a hundred mortgages, you know fifty will fail but you don’t know which. The way to make a triple A bond out of these risky mortgages is to lump them together and divide the lump into tranches that have different seniority (i.e. get paid off sequentially). So the most senior tranche will be paid off first and have the highest bond rating. If fifty of the hundred loans go bad, the senior tranche will still get paid. This is great as long as the mortgages are only weakly correlated and you know what that correlation is. However, if the mortgages fail together then all the tranches will be bad. This is what happened when the bubble collapsed. Correlations in how people responded to the collapse made it even worse. When some CDOs started to fail, people panicked collectively and didn’t trust any CDOs even though some of them were still okay. The market for CDOs became frozen so people who had them and wanted to sell them couldn’t even at a discount. This is why the federal government stepped in. The bail out was deemed necessary because of bad correlations. Just between you and me, I would have let all the banks just fail.
We can quantify the effect of correlations in a simple example, which will also show the difference between sample mean and population mean. Let’s say you have some variable  that estimates some quantity. The expectation value (population mean) is
that estimates some quantity. The expectation value (population mean) is  . The variance of ,
. The variance of , 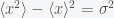 gives an estimate of the square of the error. If you wanted to decrease the error of the estimate then you can take more measurements. So let’s consider a sample of
gives an estimate of the square of the error. If you wanted to decrease the error of the estimate then you can take more measurements. So let’s consider a sample of 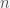 measurements. The sample mean is
measurements. The sample mean is 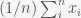 . The expectation value of the sample mean is
. The expectation value of the sample mean is  . The variance of the sample mean is
. The variance of the sample mean is
![\langle [(1/n)\sum_i x_i]^2 \rangle - \langle x \rangle ^2 = (1/n^2)\sum_i \langle x_i^2\rangle + (1/n^2) \sum_{j\ne k} \langle x_j x_k \rangle - \langle x \rangle^2](https://s0.wp.com/latex.php?latex=%5Clangle+%5B%281%2Fn%29%5Csum_i+x_i%5D%5E2+%5Crangle+-+%5Clangle+x+%5Crangle+%5E2+%3D+%281%2Fn%5E2%29%5Csum_i+%5Clangle+x_i%5E2%5Crangle+%2B+%281%2Fn%5E2%29+%5Csum_%7Bj%5Cne+k%7D+%5Clangle+x_j+x_k+%5Crangle+-+%5Clangle+x+%5Crangle%5E2&bg=f5f6f7&fg=444444&s=0&c=20201002)
Let  be the correlation between two measurements. Hence,
be the correlation between two measurements. Hence,  . The variance of the sample mean is thus
. The variance of the sample mean is thus  . If the measurements are uncorrelated (
. If the measurements are uncorrelated (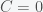 ) then the variance is
) then the variance is 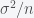 , i.e. the standard deviation or error is decreased by the square root of the number of samples. However, if there are nonzero correlations then the error can only be reduced to the amount of correlations
, i.e. the standard deviation or error is decreased by the square root of the number of samples. However, if there are nonzero correlations then the error can only be reduced to the amount of correlations  . Thus, correlations give a lower bound in the error on any estimate. Another way to think about this is that correlations reduce entropy and entropy reduces information. One way to cure our current problems is to destroy parallel correlations.
. Thus, correlations give a lower bound in the error on any estimate. Another way to think about this is that correlations reduce entropy and entropy reduces information. One way to cure our current problems is to destroy parallel correlations.
 . Then so long as
. Then so long as 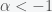 , we can make that resource last forever since
, we can make that resource last forever since  is finite. Now, if the population is growing exponentially then we would have to become exponentially more efficient with time to make the resource last. However, making the world more efficient will take good ideas and skilled people to execute them and that will scale with the population. So there might be some optimal growth rate where we ensure the idea generation rate is sufficient to increase efficiency so that we can sustain forever.
is finite. Now, if the population is growing exponentially then we would have to become exponentially more efficient with time to make the resource last. However, making the world more efficient will take good ideas and skilled people to execute them and that will scale with the population. So there might be some optimal growth rate where we ensure the idea generation rate is sufficient to increase efficiency so that we can sustain forever. , for
, for  , where
, where  is a normalization constant. Let’s say the population size is
is a normalization constant. Let’s say the population size is  and the GDP is
and the GDP is  . Hence, we have the conditions
. Hence, we have the conditions  and
and 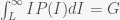 . Inserting the Pareto distribution gives the following conditions
. Inserting the Pareto distribution gives the following conditions 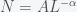 and
and  , or
, or  and
and 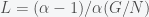 . The Pareto distribution is thought to be valid mostly for the tail fo the income distribution so
. The Pareto distribution is thought to be valid mostly for the tail fo the income distribution so  should only be thought of as an effective minimum income. We can now calculate the income threshold for the top 1% say. This is given by the condition
should only be thought of as an effective minimum income. We can now calculate the income threshold for the top 1% say. This is given by the condition  , which results in
, which results in  or
or  . For
. For  then the 99 percentile income threshold is about two hundred thousand dollars, which is a little low, implying that
then the 99 percentile income threshold is about two hundred thousand dollars, which is a little low, implying that 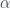 is less than two. However, the crucial point is that
is less than two. However, the crucial point is that  scales with the average income
scales with the average income  . The median income would have the same scaling, which clearly goes against recent trends where median incomes have stagnated while top incomes have soared. What this implies is that the top end obeys a different income distribution from the rest of us.
. The median income would have the same scaling, which clearly goes against recent trends where median incomes have stagnated while top incomes have soared. What this implies is that the top end obeys a different income distribution from the rest of us.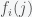 on all the integers
on all the integers  . This is the same as saying you have a list of all possible Turing machines
. This is the same as saying you have a list of all possible Turing machines  , of all possible initial states
, of all possible initial states 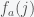 takes the output of function j given input
takes the output of function j given input  . The problem then comes if you suppose that the function acts on itself because then
. The problem then comes if you suppose that the function acts on itself because then 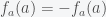 , which is a contradiction and thus such a computable function
, which is a contradiction and thus such a computable function 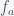 cannot exist.
cannot exist.