I had a personal situation this past year that kept me from posting much but today I decided to sit down and write something – all by myself without any help from anyone or anything. I could have enlisted the help of Chat GPT or some other large language model (LLM) but I didn’t. These posts generally start out with a foggy idea, which then take on a life of their own. Part of my enjoyment of writing these things is that I really don’t know what they will say until I’m finished. But sometime in the near future I’m pretty sure that WordPress will have a little window where you can type an idea and a LLM will just write the post for you. At first I will resist using it but one day I might not feel well and I’ll try it and like it and eventually all my posts will be created by a generative AI. Soon afterwards, the AI will learn what I like to blog about and how often I do so and it will just start posting on it’s own without my input. Maybe most or all content will be generated by an AI.
These LLMs are created by training a neural network to predict the next word of a sentence, given the previous words, sentences, paragraphs, and essentially everything that has ever been written. The machine is fed some text and produces what it thinks should come next. It then compares its prediction with the actual answer and updates its settings (connection weights) based on some score of how well it did. When fed the entire corpus of human knowledge (or at least what is online), we have all seen how well it can do. As I have speculated previously (see here), this isn’t all too surprising given that the written word is relatively new in our evolutionary history. Thus, humans aren’t really all that good at it and there isn’t all that much variety in what we write. Once an AI has the ability to predict the next word, it doesn’t take much more tinkering to make it generate an entire text. The specific technology that made this generative leap is called a diffusion model, which I may describe in more technical detail in the future. But in the simplest terms, the model finds successive small modifications to transform the initial text (or image or anything) into pure noise. The model can then be run backwards starting from random noise to create text.
When all content is generated by AI, the AI will no longer have any human data on which to further train. Human written culture will then be frozen. The written word will just consist of rehashing of previous thoughts along with random insertions generated by a machine. If the AI starts to train on AI generated text then it could leave human culture entirely. Generally, when these statistical learning machines train on their own generated data they can go unstable and become completely unpredictable. Will the AI be considered conscious by then?
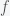 (i.e. fraction of planets with life) and this probability is uniform across the universe. Then if you search
(i.e. fraction of planets with life) and this probability is uniform across the universe. Then if you search 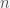 planets, the probability for the number of planets with life you will find is given by a Binomial distribution. The probability that there are
planets, the probability for the number of planets with life you will find is given by a Binomial distribution. The probability that there are  planets is given by the expression
planets is given by the expression  , where
, where  is a factor (the binomial coefficient) such that the sum of
is a factor (the binomial coefficient) such that the sum of 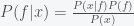
 . As expected, the posterior depends strongly on the prior. A convenient way to express the prior probability is to use a Beta distribution
. As expected, the posterior depends strongly on the prior. A convenient way to express the prior probability is to use a Beta distribution (*)
(*) is again a normalization constant (the Beta function). The mean of a beta distribution is given by
is again a normalization constant (the Beta function). The mean of a beta distribution is given by  and the variance, which is a measure of uncertainty, is given by
and the variance, which is a measure of uncertainty, is given by  . The posterior distribution for
. The posterior distribution for 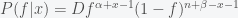
 is a normalization factor. This is again a Beta distribution. The Beta distribution is called the conjugate prior for the Binomial because it’s form is preserved in the posterior.
is a normalization factor. This is again a Beta distribution. The Beta distribution is called the conjugate prior for the Binomial because it’s form is preserved in the posterior.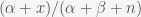 and
and 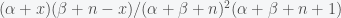 , respectively. Now let’s consider how our priors have updated. Suppose our prior was
, respectively. Now let’s consider how our priors have updated. Suppose our prior was  , which gives a uniform distribution for
, which gives a uniform distribution for  . The observation of a single planet has greatly reduced our uncertainty and we now expect about 1 in 5000 planets to have life. Now what happens if we find no planets. Then, our expected
. The observation of a single planet has greatly reduced our uncertainty and we now expect about 1 in 5000 planets to have life. Now what happens if we find no planets. Then, our expected  and
and  so our expected probability is zero with zero variance. The observation of a single planet increases our posterior to 1 in 10001 with about the same small variance. However, if we find a single planet out of much fewer observations like 100, then our expected probability for life would be even higher but with more uncertainty. In any case, Sara Seager’s intuition is correct – finding a planet would be a game breaker and not finding one shouldn’t really discourage us that much.
so our expected probability is zero with zero variance. The observation of a single planet increases our posterior to 1 in 10001 with about the same small variance. However, if we find a single planet out of much fewer observations like 100, then our expected probability for life would be even higher but with more uncertainty. In any case, Sara Seager’s intuition is correct – finding a planet would be a game breaker and not finding one shouldn’t really discourage us that much. positive tests if the person is positive is
positive tests if the person is positive is  , where
, where  is the cumulative distribution function of the Binomial distribution (i.e. probability that the number of Binomial distributed events is less than or equal to
is the cumulative distribution function of the Binomial distribution (i.e. probability that the number of Binomial distributed events is less than or equal to  . We thus want to find the minimal
. We thus want to find the minimal  and
and 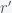 . This means that we need to solve the constrained optimization problem: find the minimal
. This means that we need to solve the constrained optimization problem: find the minimal 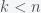 ,
,  and
and 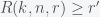 .
. 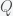 decreases and
decreases and 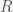 increases with increasing
increases with increasing  is your outcome function. Jensen’s inequality states that the average or expectation value of a convex function (e.g. a function that bends upwards) is greater than (or equal to) the function of the expectation value. Thus,
is your outcome function. Jensen’s inequality states that the average or expectation value of a convex function (e.g. a function that bends upwards) is greater than (or equal to) the function of the expectation value. Thus,  . In other words, if your outcome function is convex then your average outcome will be larger just by acting in a random fashion. During “convex” times, the people who just keep trying different things will invariably be more successful than those who do nothing. They were lucky (or they recognized) that their outcome was convex but their persistence and willingness to try anything was instrumental in their success. The flip side is that if they were in a nonconvex era, their random actions would have led to a much worse outcome. So, do you feel lucky?
. In other words, if your outcome function is convex then your average outcome will be larger just by acting in a random fashion. During “convex” times, the people who just keep trying different things will invariably be more successful than those who do nothing. They were lucky (or they recognized) that their outcome was convex but their persistence and willingness to try anything was instrumental in their success. The flip side is that if they were in a nonconvex era, their random actions would have led to a much worse outcome. So, do you feel lucky?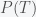 is the probability we assign to whether climate change is real;
is the probability we assign to whether climate change is real; 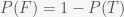 is our probability that climate change is false. In the Bayesian interpretation of probability, this would represent our level of belief in climate change. Given new data
is our probability that climate change is false. In the Bayesian interpretation of probability, this would represent our level of belief in climate change. Given new data 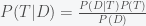
 , is equal to the probability that the new data came from our internal model of a world with climate change (i.e. our likelihood),
, is equal to the probability that the new data came from our internal model of a world with climate change (i.e. our likelihood),  multiplied by our prior probability that climate change is real,
multiplied by our prior probability that climate change is real,  divided by the probability of obtaining such data in all possible worlds,
divided by the probability of obtaining such data in all possible worlds, 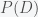 . According to the rules of probability, the latter is given by
. According to the rules of probability, the latter is given by  , which is the sum of the probability the data came from a world with climate change and that from one without.
, which is the sum of the probability the data came from a world with climate change and that from one without. then
then  . From the Bayesian update rule, the posterior will be identical to the prior. In a world of lots of misleading data, there is no update. Thus, obfuscation and sowing confusion is a very good strategy for preventing updates of priors. You don’t need to refute data, just provide fake examples and bury the data in a sea of noise.
. From the Bayesian update rule, the posterior will be identical to the prior. In a world of lots of misleading data, there is no update. Thus, obfuscation and sowing confusion is a very good strategy for preventing updates of priors. You don’t need to refute data, just provide fake examples and bury the data in a sea of noise.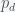 :
:
 is the probability of having a gun,
is the probability of having a gun,  is the probability of being a criminal or mentally unstable enough to become a shooter,
is the probability of being a criminal or mentally unstable enough to become a shooter,  is the probability of effective vigilante action, and
is the probability of effective vigilante action, and 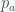 is the probability of accidental death or suicide. The probability of being killed by a gun is given by the probability of someone having a gun times the probability that they are unstable enough to use it. This is reduced by the probability of a potential victim having a gun times the probability of acting effectively to stop the shooter. Finally, there is also a probability of dying through an accident.
is the probability of accidental death or suicide. The probability of being killed by a gun is given by the probability of someone having a gun times the probability that they are unstable enough to use it. This is reduced by the probability of a potential victim having a gun times the probability of acting effectively to stop the shooter. Finally, there is also a probability of dying through an accident. and the second derivative is negative. Thus, the minimum of
and the second derivative is negative. Thus, the minimum of  and must be at the boundary. Given that
and must be at the boundary. Given that 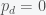 when
when  and
and  when
when  , the absolute minimum is found when no one has a gun. Even if vigilante action was 100% effective, there would still be gun deaths due to accidents. Now, some would argue that zero guns is not possible so we can examine if it is better to have fewer guns or more guns.
, the absolute minimum is found when no one has a gun. Even if vigilante action was 100% effective, there would still be gun deaths due to accidents. Now, some would argue that zero guns is not possible so we can examine if it is better to have fewer guns or more guns. 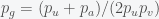 . Thus, unless
. Thus, unless  is greater than one half then even in the absence of accidents there is no situation where increasing the number of guns makes us safer. The bottom line is that if we want to reduce gun deaths we should either reduce the number of guns or make sure everyone is armed and has military training.
is greater than one half then even in the absence of accidents there is no situation where increasing the number of guns makes us safer. The bottom line is that if we want to reduce gun deaths we should either reduce the number of guns or make sure everyone is armed and has military training. on some domain
on some domain ![[x_{\min},x_{\max}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B%5Cmin%7D%2Cx_%7B%5Cmax%7D%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) and you want to generate a set of numbers that follows this probability law. This is actually very simple to do although those new to the field may not know how. Generally, any programming language or environment has a built-in random number generator for real numbers (up to machine precision) between 0 and 1. Thus, what you want to do is to find a way to transform these random numbers, which are uniformly distributed on the domain
and you want to generate a set of numbers that follows this probability law. This is actually very simple to do although those new to the field may not know how. Generally, any programming language or environment has a built-in random number generator for real numbers (up to machine precision) between 0 and 1. Thus, what you want to do is to find a way to transform these random numbers, which are uniformly distributed on the domain ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) to the random numbers you want. The first thing to notice is that the cumulative distribution function (CDF) for your PDF,
to the random numbers you want. The first thing to notice is that the cumulative distribution function (CDF) for your PDF,  is a function that ranges over the interval
is a function that ranges over the interval  between o and 1, and 2) plug it into the inverse of
between o and 1, and 2) plug it into the inverse of  . The numbers you get out satisfy your distribution (i.e.
. The numbers you get out satisfy your distribution (i.e.  ).
). then you can just plug the random numbers directly into your function, otherwise you have to do a little more work. If you don’t have a closed form expression for the CDF then you can just solve the equation
then you can just plug the random numbers directly into your function, otherwise you have to do a little more work. If you don’t have a closed form expression for the CDF then you can just solve the equation  for
for ![v[j]=\sum_{i=0}^j \rho(ih+x_{\min}) h](https://s0.wp.com/latex.php?latex=v%5Bj%5D%3D%5Csum_%7Bi%3D0%7D%5Ej+%5Crho%28ih%2Bx_%7B%5Cmin%7D%29+h&bg=f5f6f7&fg=444444&s=0&c=20201002) , for some discretization parameter
, for some discretization parameter  such that
such that 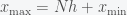 . If the PDF is defined on the entire real line then you’ll have to decide on what you want the minimum
. If the PDF is defined on the entire real line then you’ll have to decide on what you want the minimum 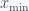 and maximum (through
and maximum (through  )
) 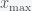 to be. If the distribution has thin tails, then you just need to go out until the probability is smaller than your desired error tolerance. You then find the index
to be. If the distribution has thin tails, then you just need to go out until the probability is smaller than your desired error tolerance. You then find the index  such that
such that ![v[j]](https://s0.wp.com/latex.php?latex=v%5Bj%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) is closest to
is closest to  .
. , to the desired PDF for
, to the desired PDF for  . Thus,
. Thus,  or
or 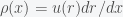 . Now,
. Now,  is the PDF of
is the PDF of 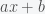 to some data. See here for the original post on
to some data. See here for the original post on 