Since, the discovery of exoplanets nearly 3 decades ago most astronomers, at least the public facing ones, seem to agree that it is just a matter of time before they find signs of life such as the presence of volatile gases in the atmosphere associated with life like methane or oxygen. I’m an agnostic on the existence of life outside of earth because we don’t have any clue as to how easy or hard it is for life to form. To me, it is equally possible that the visible universe is teeming with life or that we are alone. We simply do not know.
But what would happen if we find life on another planet. How would that change our expected probability for life in the universe? MIT astronomer Sara Seager once made an offhand remark in a podcast that finding another planet with life would make it very likely there were many more. But is this true? Does the existence of another planet with life mean a dramatic increase in the probability of life in the universe. We can find out by doing the calculation.
Suppose you believe that the probability of life on a planet is 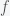 (i.e. fraction of planets with life) and this probability is uniform across the universe. Then if you search
(i.e. fraction of planets with life) and this probability is uniform across the universe. Then if you search 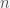 planets, the probability for the number of planets with life you will find is given by a Binomial distribution. The probability that there are
planets, the probability for the number of planets with life you will find is given by a Binomial distribution. The probability that there are  planets is given by the expression
planets is given by the expression  , where
, where  is a factor (the binomial coefficient) such that the sum of from one to is 1. By Bayes Theorem, the posterior probability for (yes, that would be the probability of a probability) is given by
is a factor (the binomial coefficient) such that the sum of from one to is 1. By Bayes Theorem, the posterior probability for (yes, that would be the probability of a probability) is given by
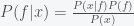
where  . As expected, the posterior depends strongly on the prior. A convenient way to express the prior probability is to use a Beta distribution
. As expected, the posterior depends strongly on the prior. A convenient way to express the prior probability is to use a Beta distribution
 (*)
(*)
where  is again a normalization constant (the Beta function). The mean of a beta distribution is given by
is again a normalization constant (the Beta function). The mean of a beta distribution is given by  and the variance, which is a measure of uncertainty, is given by
and the variance, which is a measure of uncertainty, is given by  . The posterior distribution for after observing planets with life out of will be
. The posterior distribution for after observing planets with life out of will be
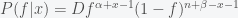
where  is a normalization factor. This is again a Beta distribution. The Beta distribution is called the conjugate prior for the Binomial because it’s form is preserved in the posterior.
is a normalization factor. This is again a Beta distribution. The Beta distribution is called the conjugate prior for the Binomial because it’s form is preserved in the posterior.
Applying Bayes theorem in equation (*), we see that the mean and variance of the posterior become 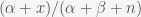 and
and 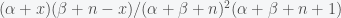 , respectively. Now let’s consider how our priors have updated. Suppose our prior was
, respectively. Now let’s consider how our priors have updated. Suppose our prior was  , which gives a uniform distribution for on the range 0 to 1. It has a mean of 1/2 and a variance of 1/12. If we find one planet with life after checking 10,000 planets then our expected becomes 2/10002 with variance
, which gives a uniform distribution for on the range 0 to 1. It has a mean of 1/2 and a variance of 1/12. If we find one planet with life after checking 10,000 planets then our expected becomes 2/10002 with variance  . The observation of a single planet has greatly reduced our uncertainty and we now expect about 1 in 5000 planets to have life. Now what happens if we find no planets. Then, our expected only drops to 1 in 10000 and the variance is about the same. So, the difference between finding a planet versus not finding a planet only halves our posterior if we had no prior bias. But suppose we are really skeptical and have a prior with
. The observation of a single planet has greatly reduced our uncertainty and we now expect about 1 in 5000 planets to have life. Now what happens if we find no planets. Then, our expected only drops to 1 in 10000 and the variance is about the same. So, the difference between finding a planet versus not finding a planet only halves our posterior if we had no prior bias. But suppose we are really skeptical and have a prior with  and
and  so our expected probability is zero with zero variance. The observation of a single planet increases our posterior to 1 in 10001 with about the same small variance. However, if we find a single planet out of much fewer observations like 100, then our expected probability for life would be even higher but with more uncertainty. In any case, Sara Seager’s intuition is correct – finding a planet would be a game breaker and not finding one shouldn’t really discourage us that much.
so our expected probability is zero with zero variance. The observation of a single planet increases our posterior to 1 in 10001 with about the same small variance. However, if we find a single planet out of much fewer observations like 100, then our expected probability for life would be even higher but with more uncertainty. In any case, Sara Seager’s intuition is correct – finding a planet would be a game breaker and not finding one shouldn’t really discourage us that much.
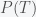 is the probability we assign to whether climate change is real;
is the probability we assign to whether climate change is real; 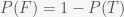 is our probability that climate change is false. In the Bayesian interpretation of probability, this would represent our level of belief in climate change. Given new data
is our probability that climate change is false. In the Bayesian interpretation of probability, this would represent our level of belief in climate change. Given new data 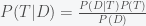
 , is equal to the probability that the new data came from our internal model of a world with climate change (i.e. our likelihood),
, is equal to the probability that the new data came from our internal model of a world with climate change (i.e. our likelihood),  multiplied by our prior probability that climate change is real,
multiplied by our prior probability that climate change is real,  divided by the probability of obtaining such data in all possible worlds,
divided by the probability of obtaining such data in all possible worlds, 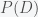 . According to the rules of probability, the latter is given by
. According to the rules of probability, the latter is given by  , which is the sum of the probability the data came from a world with climate change and that from one without.
, which is the sum of the probability the data came from a world with climate change and that from one without. then
then  . From the Bayesian update rule, the posterior will be identical to the prior. In a world of lots of misleading data, there is no update. Thus, obfuscation and sowing confusion is a very good strategy for preventing updates of priors. You don’t need to refute data, just provide fake examples and bury the data in a sea of noise.
. From the Bayesian update rule, the posterior will be identical to the prior. In a world of lots of misleading data, there is no update. Thus, obfuscation and sowing confusion is a very good strategy for preventing updates of priors. You don’t need to refute data, just provide fake examples and bury the data in a sea of noise. to some data. See here for the original post on
to some data. See here for the original post on  (1)
(1)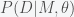 is just the parameter dependent likelihood function we used to find the posterior probabilities for the parameters of the model.
is just the parameter dependent likelihood function we used to find the posterior probabilities for the parameters of the model. (2)
(2) is an inverse temperature. The derivative of the log of the partition function gives
is an inverse temperature. The derivative of the log of the partition function gives![\frac{d}{d\beta}\ln Z(\beta)=\frac{\int d\theta \ln[P(D |\theta,M)] P(D | \theta, M)^\beta P(\theta|M)}{\int d\theta \ P(D | \theta, M)^\beta P(\theta | M)}](https://s0.wp.com/latex.php?latex=%5Cfrac%7Bd%7D%7Bd%5Cbeta%7D%5Cln+Z%28%5Cbeta%29%3D%5Cfrac%7B%5Cint+d%5Ctheta+%5Cln%5BP%28D+%7C%5Ctheta%2CM%29%5D+P%28D+%7C+%5Ctheta%2C+M%29%5E%5Cbeta+P%28%5Ctheta%7CM%29%7D%7B%5Cint+d%5Ctheta+%5C+P%28D+%7C+%5Ctheta%2C+M%29%5E%5Cbeta+P%28%5Ctheta+%7C+M%29%7D&bg=f5f6f7&fg=444444&s=0&c=20201002) (3)
(3)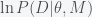 . However, if we assume that the MCMC has reached stationarity then we can replace the ensemble average with a time average
. However, if we assume that the MCMC has reached stationarity then we can replace the ensemble average with a time average 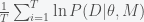 . Integrating (3) over
. Integrating (3) over 
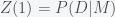 , which is what we want to compute and
, which is what we want to compute and  .
. as the likelihood in the standard MCMC) and then integrate the log likelihoods
as the likelihood in the standard MCMC) and then integrate the log likelihoods  over
over 

