Much has been written of the role of fake news in the US presidential election. While we will never know how much it actually contributed to the outcome, as I will show below, it could certainly affect people’s beliefs. Psychology experiments have found that humans often follow Bayesian inference – the probability we assign to an event or action is updated according to Bayes rule. For example, suppose 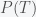 is the probability we assign to whether climate change is real;
is the probability we assign to whether climate change is real; 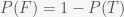 is our probability that climate change is false. In the Bayesian interpretation of probability, this would represent our level of belief in climate change. Given new data
is our probability that climate change is false. In the Bayesian interpretation of probability, this would represent our level of belief in climate change. Given new data  (e.g. news), we will update our beliefs according to
(e.g. news), we will update our beliefs according to
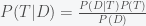
What this means is that our posterior probability or belief that climate change is true given the new data,  , is equal to the probability that the new data came from our internal model of a world with climate change (i.e. our likelihood),
, is equal to the probability that the new data came from our internal model of a world with climate change (i.e. our likelihood),  multiplied by our prior probability that climate change is real,
multiplied by our prior probability that climate change is real,  divided by the probability of obtaining such data in all possible worlds,
divided by the probability of obtaining such data in all possible worlds, 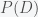 . According to the rules of probability, the latter is given by
. According to the rules of probability, the latter is given by  , which is the sum of the probability the data came from a world with climate change and that from one without.
, which is the sum of the probability the data came from a world with climate change and that from one without.
This update rule can reveal what will happen in the presence of new data including fake news. The first thing to notice is that if is zero, then there is no update. In this binary case, this means that if we believe that climate change is absolutely false or true then no data will change our mind. In the case of multiple outcomes, any outcome with zero prior (has no support) will never change. So if we have very specific priors, fake news is not having an impact because no news is having an impact. If we have nonzero priors for both true and false then if the data is more likely from our true model then our posterior for true will increase and vice versa. Our posteriors will tend towards the direction of the data and thus fake news could have a real impact.
For example, suppose we have an internal model where we expect the mean annual temperature to be 10 degrees Celsius with a standard deviation of 3 degrees if there is no climate change and a mean of 13 degrees with climate change. Thus if the reported data is mostly centered around 13 degrees then our belief of climate change will increase and if it is mostly centered around 10 degrees then it will decrease. However, if we get data that is spread uniformly over a wide range then both models could be equally likely and we would get no update. Mathematically, this is expressed as – if  then
then  . From the Bayesian update rule, the posterior will be identical to the prior. In a world of lots of misleading data, there is no update. Thus, obfuscation and sowing confusion is a very good strategy for preventing updates of priors. You don’t need to refute data, just provide fake examples and bury the data in a sea of noise.
. From the Bayesian update rule, the posterior will be identical to the prior. In a world of lots of misleading data, there is no update. Thus, obfuscation and sowing confusion is a very good strategy for preventing updates of priors. You don’t need to refute data, just provide fake examples and bury the data in a sea of noise.

3 comments inspired by caffeine, etc.)
1. Interesting and relevant topic—one i only vaguely comprehend especially in my current state. . To me Bayes theorem reduces to p(T,D)=p(T,D). Just cancel some same terms on both sides of the equation. —-change conditional probabilities to joint ones—so I dont really get the point.
(If one includes ‘time’ then P (T(t’)/D(t)) may not = P(D(t’)/P(t)) . i use / for I here–no latex. )
I also tend to think in terms of venn diagrams.
In a paper by A Caticha on bayesianism (on his website) he gives this example.
The planet mars is known to have water on it.
All planets with life on them have water on them.
Given that we know mars has water, what is the probability it has life on it.
I draw 3 circles—one big circle which is all the planets P. A smaller one inside that one which is all planets with water W. And a smaller one inside that one which is all the planets with life on them L.
So probability of life on mars is the size of the smallest circle divided by the size of the second biggest circle = L/W. . The size of the circles are guesstimates or probabilities.
He says frequentism can’t describe this as well as bayes, but i dont see the difference. He also says one can’t use frequentism because there is no data about how common life is on planets of universe.
I think there is some data (guesstimates) about how many planets P there are and how many have water W; life has one data point— so probability now is = 1/W. I guess Bostrom and F Dyson would have different estimates for L. (and if there say silicon based life one needs a different venn diagram to find L.
.
I have seen an article describing how one converts arguments using bayes theorem into the language of venn diagrams (which to me represent frequentist interpretation)—basically i remember it as being a simple excercize..
2. Given my difficulty understanding your argument, and i have a science degree, i wonder what the probability the US population or certain subgroups of it can understand your argument. (Nate Silver’s 538 says it uses bayeisianism, and they got the election wrong. A simple algorithm by someone at AU got it right.) Propoganda or noise (eg Hitler, Lippman and Bernay on ‘manufacturing consent’ and public relations) likely can trump bayesian analyses—its the addictive mental equivalent of sugar.
‘Mass hysteria’ ,or confusion, or psychosis may be like the obesity or opiate epidemics.
I’ve come across alot of people who believe in ‘conspiracy theories’—eg fake news (Bush was responsible for 911, AIDS is not caused by a virus or sex but just bad diet, loch ness monster and yetis exist, JFK and other assasination theories. …—a new one is that Trump actually wasa the one who leaked that 35 page article about sex scandals in russia). There is so much news out there its impossible to fact check and process.
The same is true of science literature—-I am attracted often mostly from a psycho-social view to ‘crank’, dissident, or woo scientific theories. (e.g. I have read alot of arguments both pro and con GMO food, vaccines, and AIDS and cancer treatments.) Peer review is supposed to sort this out, but many fields basically polarize into camps, groups or schools (eg chomskytes vs connectionists in linguistics, group selectionists vs others in biology, and still a few ‘local hidden variable’ physicists vs standard views, views of the new ‘entropic gravity’ theory—-S weinberg is even questioning quantum theory) with PhDs with good CVs on both sides. The son of a friend is big into alt-right conspiracies, thinks Sororos is the devil…I saw a music show at Planet Ping Pong which was hit by another theory.
The academics who write for the ‘ genetic literacy project’ which promotes GMOs are in constant ‘feuds’ with academics who write for ‘science for the people’, ‘council for responsible genetics’, etc. (Same thing for IQ and race issues.) Its gets more complex when one sees ‘conflict of interests’—eg koch brother funding, etc. Anti-psychiatrists dought the value of psychotropic drugs. Many people don’t trust experts sometimes for good reason (eg maybe war on Iraq, or bank bailout in 2008.)..
One sees this in global warming issue as well. Given the cold in DC recently, and the floods in drought stricken california, even i’m doing my bayesian updating for probability of anthropogenic global warming
How is anyone to know what is true, especially given cultural indoctrination, educational system, finite time and cognitive energy..
A local economist who uses bayesian methodology wrote a paper ‘information dynamics’ looking at social flows of knowledge.
3. To me this is a general issue of pattern recognition—eg can one tell if a series is random or generated by a deterministic chaotic system (classic paper in ergodic thery on this is by Ornstein and Weiss in Bull Am Math Soc in 1991).There are all kinds of ‘illusions’ or spurious correlations colllected on the blog replicated typo and in wikipedia—hot hand fallacy of Kahneman and Tversy (which likely isnt—they assumed basketball throws are as statistically independent as coin flipping which i highly dought—humans arent coins); ‘illusion of randomness’ (a great one), etc.
Slutsky-Yule theorem of 1930’s suggested in one interpretation that economic cycles were basically artifacts of data mining and aggregation—so there was actually no great depression except to economists.
.
LikeLike
p.s. The slutsky-yule theorem was used to dispute ‘hockey stick’ graph on AGW—said it was just actually random with no trend. This was written up in Am Scientist and R Mueller of UCB physics promoted it for awhile but recanted. It also came up in discussions of stuff by Scafetta of Duke U physics who also basically disputes the climate consensus—he fits climate data with higher order polynomials so he can get any trend he wants. .
LikeLike
p.s.2 I think i understand this.
One of my problems is ‘vocabulary’ — i never took probability theory, so ‘the prior’, likelhood, and posterior are foreign languages.
I studied standard markov (and non-markov) processes which have the same math (eg master equation, or path integral, or CKS equation). (I read some E T Jaynes papers but except for a few cases saw nothing much new, memorable or interesting in them. I’m not even sure if he solved any new problems—his discussion of maximum entropy applied to economics didn’t seem to have any content. Just a different dialect. )
There is also the issue of ‘order’ or ‘presentation’. This is the exact same issue as to why in schools they now put fruits and vegetables first, before french fries and ice cream—also called path dependence. Depending on the order presented, people develop ‘priors’ or theories. If given french fries first, people may decide as a prior that french fries make them feel good, and later reject any conflicting evidence. Same with say criminal behavior. There is a wide distribution of outcomes—data,
Once you have a prior (or say prejudice) any other evidence may be interpreted as noise. Just as with language learning or addiction, once you get a prior language or habit you no longer will update your ‘prior’. Humans are not infinitely malleable or plastic. (There are so many new computer languages —python, R, etc. —and i never learned any except some fairly basic C++. since i basically didn’t want to be in front of a computer all day—so i don’t update my prior. What is the reason to think python should be learned? One reason was explained to me by my niece who is going to MIT—thats how you get skills so you can get a job at facebook. I am much more in front of a computer than i should or want to be. Alot of computer stuff for me is unpaid gossip on Facebook, fact checking or education at basically elementary school level but for adults who are too busy self-promoting their own half baked ideas that they dont have time or interest in doing any research).
Some people get educated, learn python, and get big money working for facebook, while others spread fake news and ignorance on facebook. Standard Lotka-volterra dynamics. Sense and nonsense, like DNA, may be codependent. The more fake news, the higher goes the stock market.
This is why some people develop their own schools and curricula. (I know people who have done this, and i taught for awhile in an alternative school—and sort of stupidly quit that job over a semi-minor conflict).
There are like 7 B people in world—and same number of ‘priors’. There is new data or information everyday, but it will be filtered.
LikeLike
[…] is to one. Once the likelihood becomes insensitive to data then we are in the same situation as before. Technology alone, in the absence of fake news, could lead to a world where no one ever changes […]
LikeLike
Could you provide some references regarding which psychological experiments have “found that humans often follow Bayesian inference”? Sounds overly simplistic so I am skeptical.
LikeLike
@Deniz Here is a fairly recent book/review https://academic.oup.com/bjps/article-abstract/63/3/697/1548210
We’re probably not Bayes optimal all the time but for low level things like motor control, we probably are, maybe.
LikeLike
very nice for aritcl for my help in my life and other people
LikeLike