As I have posted before, I never learned any statistics during my education as a theoretical physicist/applied mathematician. However, it became fairly apparent after I entered biology (although I managed to avoid it for a few years) that fitting models to data and estimating parameters is unavoidable. As I have opined multiple times previously, Bayesian inference and the Markov Chain Monte Carlo (MCMC) method is the best way to do this. I thought I would provide the details on how to implement the algorithm since most of the treatments on the subject are often couched in statistical language that may be hard to decipher for someone with a physics or dynamical systems background. I’ll do this in a series of posts and in a nonstandard order. Instead of building up the entire Bayesian formalism, I thought I would show how the MCMC method can be used to do the job and then later show how it fits into the grand scheme of things to do even more.
Suppose you have data 
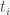


The first thing you must do is to choose an error function. The most common is the sum of square errors given by

where the 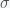

Hence, the likelihood is maximal when the error is minimal. The method of Maximum Likelihood is simply finding the set of parameters that maximizes the likelihood function.
I’ll now give the simple Metropolis algorithm to do a maximum likelihood estimation. I’ll give it in words first and then write it out in pseudo code. The first thing is to start with some initial guess for the parameter values and compute 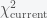


The likelihood ratio is a positive real number. You now pick a uniform random number 
In pseudo Matlab code:
theta1 = zeros(1,p); % initial guess for p parameters solve (y,theta1); % solve gives the vector y at the desired time points % for parameters theta1 chi1= sum((D - y)^2);
for n = 1: total; theta2 =theta1+ a.* randn(1,p) % p is the number of parameters and % a is the guess standard deviation solve(y,theta2); chi2=sum((D-y)^2);
ratio=exp((-chi2+chi1)/2*sigma^2);
if rand < ratio theta1=theta2; chi1=chi2; end
if n > burntime thetasave(n-burntime)=theta1; chisave(n-burntime)=chi1; end
end Pick thetasave such that chisave is minimal.
Two questions you will have is how long do you run and how do you choose the guesses. Unfortunately, there are no firm answers. A simple thing to do is to pick a Gaussian random variable around the current value as a guess. However, if you have a bound on the parameter, such as it has to be positive, then you need to use the Metropolis-Hastings algorithm, which generalizes to having non-symmetric guesses. As for how long to run, I usually just run the MCMC, increase the time and run again and see how much the answer changes. If the parameters start to converge then you can be confident that you have run long enough. In principle, if you wait long enough the MCMC will sample all of guess space and find the global optimum. In practice, it can get stuck in local minima for a long time before getting out.
Jun 29, 2015 clarification: My definition of 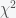

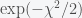

Nice article. I would love to see where this goes. I have a few questions:
If the mean square error is used as my cost function, why can’t I do simple gradient descent with multiple random initializations? I guess if you don’t have a gradient, then there’s no choice (and it’s not Bayesian). Intuitively this method seems like it’s going to take a long time to find the global optimal solution. Do you know if there is a bound on the convergence rate?
LikeLiked by 1 person
You could certainly do a gradient descent and in fact that would be the standard way of doing maximum likelihood estimates. But as you point out, you would need to estimate the gradient and you could get stuck in local minima, depending on how you choose your initial conditions. There is no guaranteed way to find global optima so it’s not clear if the MCMC is going to take longer than any other method. There are no good bounds on convergence rates. Solving that problem would be a major advance. The main reason to use MCMC is that it is the simplest way to estimate the posterior distribution.
LikeLiked by 1 person
Interesting. Thanks for the reply. :)
LikeLike
[…] model comparison By Carson Chow This is the follow up post to my earlier one on the Markov Chain Monte Carlo (MCMC) method for fitting models to data. I really should have covered Bayesian parameter […]
LikeLike
[…] is the third post on Bayesian inference. The other two are here and here. This probably should be the first one to read if you are completely unfamiliar with the topic. […]
LikeLike
Very helpful. I’m curious about the standard deviation ‘a’ though. What exactly is it? Is it the standard deviation of each of the model parameters from their accepted value and if so, what is the accepted value? Or is it the standard deviation of the current guess and the data, and if so then why would each model parameter be deviated by the same amount?
LikeLike
The standard deviation of the parameter value is the standard deviation of the posterior probability density for the parameter. If you read my other posts on Bayesian parameter estimation, the stationary distribution of the MCMC is the posterior distribution of the parameter probability given the data. Given the posterior you can then choose the mean, median, or mode to represent your best guess. However, the posterior represents the best guess of what the parameter is given the likelihood function, prior and data.
LikeLike
excellent
LikeLike
Do you have a reference or text book for the all the details?
LikeLike
Try Phil Gregory’s book.
LikeLike
Hi Carson,
What do you use as the proposal distribution for choosing the next guess for the parameter values? I assume it it symmetric since the accept/ reject step is determined purely by the likelihood ratio. Am I also right in assuming that your algorithm uses uniform priors (again because the accept/reject step only depends on the likelihood ratio)?
LikeLiked by 1 person
Hi Kenny,
All excellent questions. I usually use a Normal proposal distribution around my current point. What do you mean by symmetric? If you mean bigger or smaller than your current value then it doesn’t need to be. If you mean symmetric between swapping proposal point and current point then it does for Metropolis but not for Metropolis-Hastings, which I did not cover. The prior will be uniform if you let the MCMC roam anywhere. However, if you put boundaries on where it can go then you have effectively included a prior on that domain. You could also modify the proposal distribution depending on where you are, which is like adding a prior.
LikeLiked by 1 person
Thanks Carson!
LikeLike
Hi Carson,
I also wanted to ask you about some reference information about your research in obesity. I just finished ( May 2012) my PhD in applied math from Brown (with a focus on probability, stats, and numerical analysis) and I have been reading your blog in Obesity. I am really interested in your work and I was wondering what would be some good introductory text and/or paper to help become more familiar with your research.
Best,
Kenny
LikeLike
Good question. People have suggested that I write a book:). In terms of my research, this link has all of my obesity references
https://sciencehouse.wordpress.com/2012/05/23/references/
The PLoS Comp Bio paper is a good place to start. The Lancet series summarizes the applications of the model. There is a good book by Keith Frayn on Human metabolism.
LikeLike
Interesting your procedure. It is posible for you to post a working example with few data even using a linear funtion for y (model)?
LikeLike
@Fernando, do you mean the full code or the outputs?
LikeLike
[…] on before, one of the best ways to find an optimal solution to a problem is to search randomly, the Markov Chain Monte Carlo method being the quintessential example. Randomness is useful for searching in places you […]
LikeLiked by 1 person
Hi Carson,
One doubt: is this likelihood always between 0 and 1? i have tried to replicate this code and i am seeing values above 1. I was assuming it would have to be [0,1] for the comparison to the uniform number to make sense (or even the definition of the likelihood). Could you please let me know what i am missing?
Thanks for the entry!
LikeLike
Likelihood is not a probability. It can be any nonnegative number.
LikeLike
[…] parameters can be accomplished using the Markov Chain Monte Carlo, which I summarized previously here. We will start by defining the partition […]
LikeLike
Carson,
Thx for your post, it has helped me to learn and progress in this important area of Bayesian inference. I’ve played with some home-brewed MCMC today and have been able to fit a few models nicely. However, when generating samples without any noise as incoming data (e.g. perfectly sitting on a line in case of a linear model ax+b),
the means of the two MCMC chains converge nicely to the true a and b, but the posterior distributions of a and b are still pretty wide, and practically independent on the width of the MCMC updating process.This translates into quite some residual uncertainty in the fit parameters, no matter how many ‘perfect on a line’ datapoints were entered. Intuitively, I would say that there is hardly any uncertainty left. How should I interpret the wide distributions of a and b?
Peter
LikeLike
A likelihood is definitely a probability. A likelihood ratio is not.
LikeLike
@Pierre A likelihood is not a probability because the integral over that conditional variable need not be one. So while \int P(x|a) dx= 1, \int P(x|a) da does not need to be 1. In some cases, it will be 1 in which case it acts like a probability but there is no constraint that it must.
LikeLike
Thanks for the most comprehensive introduction to MCMC that I’ve seen to date!
I may have missed something fairly basic here, but could you possibly explain the reasoning behind comparing the likelihood ratio to a random number between 0 and 1 (rather than just 1)?
LikeLike
@Jane If you only compared the likelihood ratio to 1 then you are in effect doing a gradient descent, which can get trapped in local minima. Comparing to a random number let’s you go “uphill” every once in awhile. The MCMC will then wander over the objective function landscape, spending more time when the likelihood is high and less time when it is low. The histogram of the parameter values it visits in this wandering trek is proportional to the Bayesian posterior of this parameter.
LikeLike
OK, that makes sense. Thank you very much for the post and your reply.
LikeLike
Hi Carson Chow, nice post. Do you have any reference for this method? I would greatly appreciate that.
-Valerio
LikeLiked by 1 person
@Valerio There are many textbooks on Bayesian Inference. Gregory’s book is pretty good if you’re a physicist and Gelman et al. is good if you have more of a stats background.
LikeLike
Hi Carson Chow, thank you very much for your reply.
I got the second book. Unfortunately I cannot find the part about Markov Chain Monte Carlo and Chi Square. I am interested precisaly in that. Your method is interesting, but I am not sure it is correct, so I was looking for any other source that presented it. Is this method (applying MCMC to X^2) your invention?
Valerio
LikeLike
Gelman should cover both Gibbs sampling and MCMC. The MCMC method I use goes back to the 60’s or even 50’s.
LikeLike
Dear Vaaal,
Have a look here: http://adsabs.harvard.edu/abs/2005AAS…207.6822D
LikeLiked by 1 person
Jose, I cannot follow that link, can you give me the doi or the article title? Thank you very much!
LikeLike
Sorry, something is wrong with the URL. Try google: ” A Comparison of Least-Squares and Bayesian Techniques in Fitting the Orbits of Extrasolar Planets.” by Driscoll, P.; Fischer, D.
LikeLike
[…] test. What I want to do is to fit networks of coupled ODEs (and PDEs) to data using MCMC (see here). This means I need a language that loops fast. An example in pseudo-Matlab code would […]
LikeLike
sir,
can you post pseudo code for estimating two parameters(a,b) in a linear fit (ax+b). actually i working on it. but i am not satisfied with the results i am getting. so it will be helpful if you post pseudo code
LikeLike
[…] code for an MCMC algorithm to fit a linear model to some data. See here for the original post on MCMC. With a linear model, you can write down the answer in closed form (see here), so it is a good […]
LikeLike
Hi all (and specially Carson),
First of all, thanks for your post, Carson. Where can I read more about the justification behind constructing a likelihood function like you do ? If you have a reference which is understandable for an engineering mathematics level, that would be great.
For parameter estimation in a DAE model considering data with replicates:
I had thought to determine the likelihood of the data given a certain run of the model with certain values of parameters this way:
1- Run the deterministic model, retrieving the observed variable output value, for a certain value of the independent variable which I have measurements.
2- Think of this output values as the mean of a gaussian distribution, its variance coming from an estimation of the observed values variance (since I have replicates I can do this for each value of the independent variable).
3- The likelihood of the data given this value of parameters becomes the product of each observed replicate’s probability in the gaussian distribution constructed around the output of the model.
Does this procedure make any sense ? Is it equivalent to just using a least-squares likelihood like you do around the observed mean for each value of the independent variable ?
I would appreciate any help or reference
LikeLike
@Claudio A book on Bayesian inference meant for physicists and engineers is one by Phil Gregory
http://www.cambridge.org/us/academic/subjects/statistics-probability/statistics-physical-sciences-and-engineering/bayesian-logical-data-analysis-physical-sciences-comparative-approach-mathematica-support
Determining the likelihood function depends on what you are interested in. The least squares likelihood in my example is used in a normal distribution so I believe my example produced is the same as yours. The sum of squares in the exponent of a Gaussian is equivalent to the product of individual Gaussians.
LikeLike
Hi Carson,
do you have a reference for choosing the sigma in the likelihood function? I like your article and but a paper or book reference would help me a lot.
Thanks!
Eike
LikeLike
@Eike There is no set formula for choosing sigma. It is your expected error for the data. You can either use the actual standard deviation of your error or estimate one. Sometimes, we will fit a smooth curve through the points and use the residual as an estimate. Here is one of my papers that you could look at
https://sciencehouse.wordpress.com/2008/08/15/new-paper-on-insulins-effect-on-free-fatty-acids/.
LikeLiked by 1 person
I learned a lot from your article. I have a question about a in theta2 =theta1+ a.* randn(1,p). I still did not understand how to get this a. And is this a the same for all the parameters, or for different parameters we have different a.
Thanks
LikeLike
@Xiao There is no rigorous theory behind the choice of a. The algorithm will work for any choice. You want a to be as big as possible so you search more space but not so small that you never accept any guesses. A general rule of thumb is to choose an a so that the MCMC algorithm is accepting a guess about one third of the time. There is still a lot of art in parameter fitting.
LikeLike
@Carson Thank you for your reply. What I want to do is to use the sum of several gaussian function to fit my data. I wrote a matlab code based on the pseudo code. I tried to change different a, but the result is quite different every time. It does not converge. Do you mind my sending my data and code to you and have a look at it?
Thanks
LikeLike
@Xiao Do they fit your data? Maybe your problem is ill posed and there are many possible solutions.
LikeLike
@Carson They fit my data. I have tried nonlinear least square and EM algorithm to use Gaussian function to fit my data. And they can give me a pretty good result. I just want to try to use this method on my problem.
LikeLike
[…] models to data, dealing with local minima is a major problem and the reason that a stochastic MCMC algorithm that does occasionally go uphill works so much better than gradient descent, which only goes […]
LikeLike
Excellent post. It helped me starting out with MCMC parameter estimation. May I ask how fitting positive parameters only work in practice?
“However, if you have a bound on the parameter, such as it has to be positive, then you need to use the Metropolis-Hastings algorithm, which generalizes to having non-symmetric guesses. ”
More specifically, how do I generate a new parameter proposal? And what happens to the likelihood function? I’m a real beginner so please excuse my ignorance.
LikeLike
@rblilja You can keep parameters positive by choosing a positive only distribution such as a gamma distribution or a truncated normal distribution, i.e. a normal distribution where you ignore negative numbers. Let g(x’ | x) be the guess probability density, i.e. given positive current x’ select positive x with probability g(x’ | x) dx. Make sure to normalize g. The modification to the MCMC is the Hastings part of Metropolis-Hastings. Instead of using the ratios of likelihoods, you test with this function (P(D | x’)g(x | x’))/(P(D | x)g(x’ | x)).
LikeLike
@Carson Thank you. I decided to go for a gamma distribution as target, ending up with the Matlab code below. I have as well been inspired by the examples found here: https://darrenjw.wordpress.com/2012/06/04/metropolis-hastings-mcmc-when-the-proposal-and-target-have-differing-support/
I’m not sure I followed your advice entirely, but I end up with results that looks feasible and are quite consistent from run to run. I’m not sure how to calculate the guess probability for the acceptance ratio since I’m using different standard deviations when generating a new proposal (param_sigma). Perhaps I’m doing this completely wrong?
If you can point out any mistakes or suggest an improvement I would be more than happy. Probability is a weak spot for me.
% Init all vectors and matrices, setup initial theta and calculate initial cost etc.
data_sigma = 1.0;
param_sigma = [0.01 0.1 0.01 1.0];
…
for i=1:iterations
% Generate a non-negative proposal
theta_proposal(i,:) = theta_current(i,:) + param_sigma.*randn(1, dim);
%
while sum(theta_proposal(i,:) < zeros(1,dim))
theta_proposal(i,:) = theta_current(i,:) + param_sigma.*randn(1, dim);
end
% Evaluate cost of proposed theta (fcost = sum((data-f(theta)').^2);)
chi_proposal(i) = fcost(theta_proposal(i,:), data) / 2*data_sigma*data_sigma;
% Gamma(2,1) target distribution
P_proposal = chi_proposal(i)*exp(-chi_proposal(i));
P_current = chi_current(i)*exp(-chi_current(i));
% Guess probability density
g_proposal = normalCdf(chi_proposal(i), 0, 1); % what sigma to use here?
g_current = normalCdf(chi_current(i), 0, 1); % what sigma to use here?
% Calculate acceptance ratio
acceptance_ratio(i) = P_proposal*g_current / P_current*g_proposal;
fprintf('Iteration %d of %d:\n', i, iterations);
fprintf('\tTheta current: %s\n', sprintf('%f ', theta_current(i,:)));
fprintf('\tTheta current cost: %f\n', chi_current(i));
fprintf('\tTheta proposal: %s\n', sprintf('%f ', theta_proposal(i,:)));
fprintf('\tTheta proposal cost: %f\n', chi_proposal(i));
uniform(i) = rand;
% Descide if taking the proposed step
if uniform(i) < acceptance_ratio(i)
% Take step
theta_current(i+1,:) = theta_proposal(i,:);
chi_current(i+1) = chi_proposal(i);
else
% Remain
theta_current(i+1,:) = theta_current(i,:);
chi_current(i+1) = chi_current(i);
end
end
LikeLike
I just would like to emphasise that sometimes sigma in the Chi square is important. If you have two models that give two different fits (one better than the other) and that you compute the 2 Chi squares, depending on your observed data, the value will be very different with and without sigma. In other words, if you have data lying on a large range of Y values (several order of magnitude), then, without sigma, the low Y values will have a lower importance than the high Y values, as such, when the model is completely wrong at reproducing the low Y values, the Chi square won’t change much compare to a good model, as long as the large Y values are well represented. If you add a sigma (could be 1% of the observed data), then the low Y values will have the same “weight” as the large Y values, and the relative Chi square between two models, one representing well the low Y values and one badly representing the low Y values will be much larger. Hope I’m clear, not easy to explain with word, but I think this is important to say since in your text you mention that sigma is not a determinant parameter.
LikeLiked by 1 person
Very helpful. Thanks a lot for posting this.
LikeLike
good job is very helpfull
LikeLike
Hey,
Finally someone who doesn’t talk in abstractions only! I was struggling to find a way to choose the likelihood in order to compute the ratio. So, I decided i would use the squared error as it is ((realData – f(x/current_theta..) ^2), and then obviously do: ((realData – f(x/new_theta..) ^2)/((realData – f(x/current_theta..) ^2) . My algorithm converged really fast to the actual parameters!
However, I still wasn’t sure if what I was doing was actually MCMC/Metropolis-hastings, and then I found your post describing what you did. I find it to be quite similar to mine, except you used the Chi error and then exponentiated it!
What do you think of my approach?
Regards
LikeLike
@ Joseph. This is fine if you only care about finding the minimum error. However, your likelihood function is a quadratic function, which is nonstandard, so if you are trying to compute s posterior you must keep that in mind.
LikeLike
@Carson, I assumed that the likelihood is proportional to the squared error. Which is a fair assumption I believe, and that computing the ratio of the squared errors would be proportional to the real likelihood value.
What do you mean when you say that “if you are tying to compute the posterior you must keep that in mind”?
You mean if I am not trying to simply sample and not estimate the parameters?
LikeLike
@Joseph No, the likelihood is the “inverse” of a probability distribution. It differs in that it is not normalized. Bayes theorem gives the formula to normalize a likelihood. The squared error is the log likelihood of a Gaussian distribution. What your formulation is doing is some sort of stochastic gradient descent. It is not Metropolis algorithm per se. In Metropolis, you are trying to maximize likelihood. You are trying to minimize error. So, in the the Metropolis algorithm you “go up hill” while you are going “down hill”. If all you care about is minimizing error then your algorithm will work. So would randomly guessing to find the best answer. The advantage of Metropolis algorithm is that you presume that the “error” obeys some distribution and you are trying to find the maximum of that distribution by searching through parameter space. In other words, you are trying to find the best distribution to fit your errors, i.e. deviation of data from model. That converged distribution is then the posterior distribution of your parameters under the presumed likelihood in the Bayesian inference framework. I have written several blog posts on Bayesian inference so you might want to read those. Bottom line is that if you only care about finding a set of parameters that minimizes some error then your algorithm is fine. If you want to do something within a Bayesian framework then it will not.
LikeLike
@Carson, oh I see! It’s like I am doing some form of “Least Square Approach” to minimise the error. Except that instead of using gradient descent and computing the derivative of the function, I am borrowing the ratio component from Metropolis and using that to decide if I should update my current theta. This approach seems to be fine especially if the derivative of the chosen error is analytically intractable, thus preventing gradient descent from being used.
I am interested in getting into Bayesian inference, which posts of yours would you recommend? Also, do you know of any good books?
Many thanks for your great explanations man!
LikeLike
If you search for Bayes or Statistics on my Blog, you can find my posts although technical posts will be mixed with applications in real life. If you are a physicist, good books to start with are those by David McKay (Information Theory, Inference and Learning Algorithms) and Phil Gregory (Bayesian Logical Data Analysis for the Physical Sciences). If you like philosophy there is the book by Edwin Jaynes and if you are coming from math/stats then there is the classic book by Andrew Gelman and colleagues.
LikeLike
Reblogged this on systems perestroika – éminence grise.
LikeLike
[…] the net for a while, without finding any good info on the topic, but a few days ago, I found these two links that provided some input on the problem, and what follows, is based on that […]
LikeLike
Thank you Carson, great article!
Eventually one needs to “Pick thetasave such that chisave is minimal”. I wonder, Is there a way to interpret the results to obtain uncertainties/error around the parameters?
From what I understood, in other, more straightforward implementation of MCMC, the parameters are eventually obtained by taking the mean of each parameter and one can also calculate the std for an estimation of the uncertainty. Is this also an option here?
Best,
LikeLike
@tomer Yes, once converged (for which there are no theorems to say when that happens), the distribution from which MCMC sample series is drawn is the posterior distribution of the parameter. I have been meaning to write a follow up for years explaining the Bayesian interpretation of MCMC. Thus the mean of the samples is the mean of the posterior and the std is the std of the posterior. But you actually have the whole distribution and the more Bayesian way is to take the 95% credible interval around the median.
LikeLike
Hey Carson,
A really nice article. The reason that I like your explanation so much is that unlike most explanations, it tied together the total output of the model. What I mean by that is if you use MCMC to find the most optimal solution, then the standard deviation or jump factor doesn’t matter as much. Whether the tail is somewhat fatter doesn’t change the optimal solution. For my purposes, however, I need the standard deviation of the output to make sense because I use the output as a distribution. I like the X2 because you can see where the standard deviation comes from. Also, the number of points in the data set will affect the shape since more points should mean a greater spread in the cost which will limit the distance of the jumps. This makes sense since less data should imply more variability than more data points. Anyway, thanks a bunch.
LikeLike
@BladdyK Thanks. I’ve been meaning to write the sequel to this for a decade now but the samples drawn from the MCMC will approximate that being drawn from the posterior distribution of that parameter. If you run forever, it is guaranteed to converge to the posterior but there are no theorems to tell you how long is long enough. Also, you can get faster convergence if you put a good prior on the parameters.
LikeLike