When simulating any system with randomness, sampling from a probability distribution is necessary. Usually, you’ll just need to sample from a normal or uniform distribution and thus can use a built-in random number generator. However, for the time when a built-in function does not exist for your distribution, here’s a simple algorithm.
Let’s say you have some probability density function (PDF)  on some domain
on some domain ![[x_{\min},x_{\max}]](https://s0.wp.com/latex.php?latex=%5Bx_%7B%5Cmin%7D%2Cx_%7B%5Cmax%7D%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) and you want to generate a set of numbers that follows this probability law. This is actually very simple to do although those new to the field may not know how. Generally, any programming language or environment has a built-in random number generator for real numbers (up to machine precision) between 0 and 1. Thus, what you want to do is to find a way to transform these random numbers, which are uniformly distributed on the domain
and you want to generate a set of numbers that follows this probability law. This is actually very simple to do although those new to the field may not know how. Generally, any programming language or environment has a built-in random number generator for real numbers (up to machine precision) between 0 and 1. Thus, what you want to do is to find a way to transform these random numbers, which are uniformly distributed on the domain ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) to the random numbers you want. The first thing to notice is that the cumulative distribution function (CDF) for your PDF,
to the random numbers you want. The first thing to notice is that the cumulative distribution function (CDF) for your PDF,  is a function that ranges over the interval , since it is a probability. Thus, the algorithm is: 1) generate a random number
is a function that ranges over the interval , since it is a probability. Thus, the algorithm is: 1) generate a random number  between o and 1, and 2) plug it into the inverse of
between o and 1, and 2) plug it into the inverse of  . The numbers you get out satisfy your distribution (i.e.
. The numbers you get out satisfy your distribution (i.e.  ).
).
If you’re lucky enough to have a closed form expression of the inverse of the CDF  then you can just plug the random numbers directly into your function, otherwise you have to do a little more work. If you don’t have a closed form expression for the CDF then you can just solve the equation
then you can just plug the random numbers directly into your function, otherwise you have to do a little more work. If you don’t have a closed form expression for the CDF then you can just solve the equation  for
for  . Newton’s method will generally converge very quickly. You just loop over the command x = x – (P(x)-r)/rho(x) until you reach the tolerance you want. If you don’t have a closed form expression of the CDF then the simplest way is construct the CDF numerically by computing the N dimensional vector
. Newton’s method will generally converge very quickly. You just loop over the command x = x – (P(x)-r)/rho(x) until you reach the tolerance you want. If you don’t have a closed form expression of the CDF then the simplest way is construct the CDF numerically by computing the N dimensional vector ![v[j]=\sum_{i=0}^j \rho(ih+x_{\min}) h](https://s0.wp.com/latex.php?latex=v%5Bj%5D%3D%5Csum_%7Bi%3D0%7D%5Ej+%5Crho%28ih%2Bx_%7B%5Cmin%7D%29+h&bg=f5f6f7&fg=444444&s=0&c=20201002) , for some discretization parameter
, for some discretization parameter  such that
such that 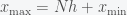 . If the PDF is defined on the entire real line then you’ll have to decide on what you want the minimum
. If the PDF is defined on the entire real line then you’ll have to decide on what you want the minimum 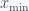 and maximum (through
and maximum (through  )
) 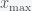 to be. If the distribution has thin tails, then you just need to go out until the probability is smaller than your desired error tolerance. You then find the index
to be. If the distribution has thin tails, then you just need to go out until the probability is smaller than your desired error tolerance. You then find the index  such that
such that ![v[j]](https://s0.wp.com/latex.php?latex=v%5Bj%5D&bg=f5f6f7&fg=444444&s=0&c=20201002) is closest to (i.e. in Julia you could use findmin(abs(v[j]-r))) and your random number is
is closest to (i.e. in Julia you could use findmin(abs(v[j]-r))) and your random number is  .
.
Here is why the algorithm works. What we are doing is transforming the PDF of , which we can call  , to the desired PDF for . The transformation we use is
, to the desired PDF for . The transformation we use is  . Thus,
. Thus,  or
or 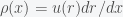 . Now, is just 1 on the interval and
. Now, is just 1 on the interval and  is the PDF of as expected. Thus, inverting the CDF for uniform random numbers always gives you a new set of random numbers that satisfies the new PDF. Trivial perhaps, but really useful.
is the PDF of as expected. Thus, inverting the CDF for uniform random numbers always gives you a new set of random numbers that satisfies the new PDF. Trivial perhaps, but really useful.
Erratum: 2019-04-05. It was pointed out to me that my algorithm involving direct summation of the CDF had some errors. I hope they have now been corrected.

these are the kind of math issues i like (though can’t solve, and also am not much into programming/simulating, somewhat for ideological and aesthetic/personal preference issues—i am often impressed by what planes, computers, electrical instruments, and other technologies can do but i prefer walking, acoustic music, pencil and paper—its almost impossible to ‘live off the grid’ and be in touch with reality—indigenous peoples are going the way of endangered species, and bloosburg predicts anone who can’t code will be history very soon in terms of employment and economic survival (though perhaps a few right wing talk radio hosts, steve colbert, george will, etc. will still have a niche).
i was always into ‘multimodal probability distributions’ (usually fitted by mixtures it seems, or maybe wavekets). This is because things like mountain ranges, geographies, species distributions, etc. do not appear to be uniform, gaussian, exponential, power, etc. However, one can often clump the data so they are —eg rather than look at the earth’s surface, you just divide it into ‘cells’, meusre the elevations, ranjk them and you’ll probably get some ‘normal’ one. Its not useful for hiking though–you need a topo map.
Nonlinear and multidimensional functions are better fits to topo maps or other kinds of distributions (even income distributions, which typically can fit into the standard ones, often have a bit more structure—neigjhborhoods vary fairly widely in income, as do professions (even if people work in the same building).
This raises an issue for me—if you have a nonlinear function describing your system or sample, does this imply it is not randomly generated, but rather a determinstic process? (The old issue of determining whether a time series—eg stock market—is random or not. (my impression is basically in general its impossible to know).
I think there are urn models (possibly going back to feller) and also approaches based on potential theory (perhaps doob) that more or less solve the problem with the same result from 2 different directions (sort of like verlinde’s entropic gravity—and i think there are similar ideas around in other fields—an ‘entropic (random) force’ can look like a newtonian one when written down ( discussions like this appear in nonequilbrium thermodynamics, ecology, and income distribution).
It might also seem that if one can fit an arbitrary probability distribution with some ‘tweaking’ or deformation of a standard random number generator, then one might be able ‘lie about anything with statistics’. Sort of like modern polling—if you only call people with landlines, or cell phones, or go door to door asking questions when all the ‘evening shift workers’ are at work, you’ll get a skewed sample. One may then be able to socially construct a scientific theory. (perhaps the breast cancer/estrogen issue falls into such a class).
LikeLike
@ishi Not sure what you mean about nonlinear function and randomness but there is no way to tell a high dimensional system from a truly random one if you just had a time series. However, if you measured the attractor dimension and found that it was low dimensional, then it is likely to be generated by a deterministic chaotic system. My take is that low dimensional chaos is very rare in nature so anything that looks noisy is likely to be high dimensional.
LikeLike
just a note—i am so rusty on all the definitions but
1) i think i agree with most of your comment—-the paper (i think a classic) by Ornstein and Weiss in BAMS (Bull Am Ma Soc) 1991 ‘statistical properties of chaotic systems’ (free online) which you likely know runs through some of the issues. i have seen only one discussion of this paper by an economist, though economic time series are a huge topic. (I like the yule-slutsky 1930’s theorem on this—spurious cycles—‘data mine your way to a great depression’ —a sort of funny approach to R Lucas’ ‘rational expectations’ view–‘there is no involuntary unemployment, just a labor-leisure conservation law—lagrangians for everything —see fox news–
http://www.arxiv.org/abs/1506.01293
(james crutchfield of SFI has similar stuff on conservation laws, which i gather john muir and jerry brown have instituted for some reason in california).
interestingly, the slutsky-yule theorem came up when people were trying to show that the in/famous ‘hockey stick’ graph of Mann realclimate.org blog ) purporting to show there is ‘global warming’ was nothing more than due to how you smoothed your time series –N Scafetta, and B West, of Duke U–also fit the data with high order polynomials. (my data set says its 96 degrees now, but its going down to 70 tonite, so how is that warming?)
i also once saw james yorke talk on trying to determine whether some system was chaotic, or just appeared to be due to computer roundoff error–he said he proved it was chaotic (reminds me of the classic FPU computer experiments for ergodicity in the 40’s or 50’s).
i am agnostic as to whether low diemsnional chaos is rare i nature, especially since its hard if even possible to tell whether anything is random or deterministic.. its more like a heursitic decision or act of faith.
2) your algorithm actually appears to be similar conceptually to the maximum entropy inverse method—start with your constraints, and then you will know ‘what the shape of a drum is’ (marc kac—who i once saw talk—1 of the 3 in my trinity of great talks —others were j wheeler (physics), and h simon (econ). (the one on poincare conjecture didnt fit into a trinity but was good too). . (regarding ‘nonlnear function and randomness’ what i am basically trying to say in a very general way is, for example, if you have some data, and then conssider all possible regressions or curve fittings, and then dream up some combinatoric system that might generate those data points, and find the most probable one (using maxent) , then you choose that curve.
(r k niven on arxiv sortuh explains this).
this is just a recipe—you can use maxent to generate curves describint the income distribution quite well, but you can also generate the same curve using ideas about maximizing utility, work, effort, talent etc.—it could be ‘luck’ or ‘merit’.
(in nature, i can often predict what i will find based on how big the area is, and other constraints—roads, development,etc. i sometimes find endangered (at least locally) species which shouldnt be there but i figure i’ll find some and do).
3) my ‘cafe philo’ group is discussing ‘what is randomness’ this week. one person (into math logic) cites leibniz (pcp of insuffiencent reason)and says there is no randomness. i was thinking more along the lines of chaitin and random real number—basically everything (reality) is random (choose an arbitrary real number, and try to predict its binary sequence–you win a 1$ coupon for mcdonalds if you get it correct; extra credit for prediciting if a random integer is a prime (u cant use a prime generating algorithm), or if u can randomly throw a dart at the real line and hit something rational.. what we call ‘reality’ is just arbitrary truncations of some arbitrary infinite binary expansion. ‘time is up’. (others go into whether Quantum theory is deterministic or not; i view it the same way—k/notted nots)
LikeLike
Tough it is less efficient, doesn’t the following iterative approach also work? Generate two random numbers: (1) x from some standard distribution (e.g. uniform) on the interval [xmin,xmax], and (2) u from a uniform distribution on the interval [0,1]. While rho(x) = u. Then x will follow the PDF rho(x).
There is a brief mention of this iterative approach for an exponential distribution here: http://preshing.com/20111007/how-to-generate-random-timings-for-a-poisson-process/. However, he says to use the CDF instead, which I think is incorrect. He also adds an interesting comment about a dependence on numerical precision that I didn’t understand.
LikeLike
CORRECTION: A part of my post didn’t appear correctly. Where it shows “rho(x) = u”, the intended text should have been:
While rho(x) is less than u, regenerate x and u until rho(x) is greater than or equal to u.
I used math symbols, which seems to have messed something up.
LikeLike
@Chris It seems like the link you give uses the same method I presented, which is not my method by any means.
LikeLike
@Carson: That page I mentioned discusses both methods (iterative/brute-force vs. using the CDF). They are both discussed in “Writing a Simulation”. As I said, I think it incorrectly says to use the CDF for the brute-force approach, when it should be the PDF. The inefficiency lies in the fact that you will waste time generating numbers that are rejected.
LikeLike
@chris Maybe I’m misunderstanding the link but I don’t see your algorithm at all. What I see in their brute force method for a Poisson process is that at each time point X you ask if the event has happened or not. You can do this two ways. The super brute force way is to flip a coin with a probability of \lambda dX of being heads and collect the X value whenever you get heads. A more subtle way is what the site proposes which is to generate a uniform random number u and collect X when F(X) is less than u.
With your method, which is different, I think you mean: keep X when \rho(X) dX is greater than u (not \rho(X), which is not bound between 0 and 1). In any case, your strategy is to keep X in proportion to \rho(X).
LikeLike
Simple and beautiful. Thanks for posting.
LikeLike
I’m setting up a quasi importance sampling like scheme wherein we spawn a number of samples at a given x, whose number is proportional to the pdf’s value at that point.
LikeLike
[…] https://sciencehouse.wordpress.com/2015/06/20/sampling-from-a-probability-distribution/ […]
LikeLike
There is a sign error in
by computing the N dimensional vector $ v[j]=\sum_{i=0}^j \rho(jh – x_{\min}) h $
$\rho(jh + x_{\min})$
Very useful post, thanks.
LikeLike
@Pierre Thanks for pointing out the error. I hope I have now corrected it.
LikeLiked by 1 person
I think it’s worth noting that this algorithm will generate one of many possible sets that follow the requested probability distribution. The “a” in your quote “you want to generate a set of numbers that follows this probability law” is very important. For example, using the same algorithm but adding a sorting step at the end would yield a dataset with the exact same probability distribution, but the resultant dataset will have much more structure than perhaps intended. It’s also worth noting that the probability distribution alone is not sufficient to replicate the original random process that generated the data points. It could miss other properties of the data, as is highlighted in the datasaurus dataset [1] as well as the dozen other similar datasets [2]
[1] http://www.thefunctionalart.com/2016/08/download-datasaurus-never-trust-summary.html
[2] https://www.autodesk.com/research/publications/same-stats-different-graphs
LikeLike
Thanks for your comment
LikeLike