One of the most useful theorems in applied mathematics is the Fredholm Alternative. However, because the theorem has several parts and gets expressed in different ways, many people don’t know why it has “alternative” in the name. For them, the theorem is a means of constructing solvability conditions for linear equations used in perturbation theory.
The Fredholm Alternative Theorem can be easily understood if you consider solutions to the matrix equation  , for a matrix
, for a matrix  and vectors
and vectors  and
and  . Everything that applies to matrices can then be generalized to infinite dimensional linear operators that occur in differential or integral equations. The theorem is: Exactly one of the two following alternatives hold
. Everything that applies to matrices can then be generalized to infinite dimensional linear operators that occur in differential or integral equations. The theorem is: Exactly one of the two following alternatives hold
- has one and only one solution
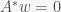 has a nontrivial solution
has a nontrivial solution
where 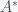 is the transpose or adjoint of A. However, this is not the form of the theorem that is usually used in applied math. A corollary to the above theorem is that if the second alternative holds then has a solution if and only if the inner product
is the transpose or adjoint of A. However, this is not the form of the theorem that is usually used in applied math. A corollary to the above theorem is that if the second alternative holds then has a solution if and only if the inner product  , where
, where 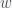 is in the nullspace of the adjoint of A, i.e.
is in the nullspace of the adjoint of A, i.e. 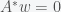 . The condition is then a solvability condition for an operator equation (e.g. differential or integral equation) that can be used in perturbation theory. One can clearly see that if the theorem is stated this way, the “alternative” is obscured.
. The condition is then a solvability condition for an operator equation (e.g. differential or integral equation) that can be used in perturbation theory. One can clearly see that if the theorem is stated this way, the “alternative” is obscured.
The reason the theorem is true is the basis for the theory of the solution of linear systems, and Gilbert Strang even calls it the fundamental theorem of linear algebra (not to be confused with the fundamental theorem of algebra). There are four fundamental subspaces for an 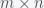 matrix A. There is the column space, which is the subspace defined by the columns of the matrix. This is also called the range or image of A. There is the row space, which is the subspace where the rows live. Since this is just the column space of the adjoint, it is also the range or image of the adjoint. Then there is the subspace of the vectors w for which
matrix A. There is the column space, which is the subspace defined by the columns of the matrix. This is also called the range or image of A. There is the row space, which is the subspace where the rows live. Since this is just the column space of the adjoint, it is also the range or image of the adjoint. Then there is the subspace of the vectors w for which  . This is called the nullspace or kernel of A. Finally, there is the nullspace of the adjoint, often called the left nullspace.
. This is called the nullspace or kernel of A. Finally, there is the nullspace of the adjoint, often called the left nullspace.
The dimension of the column space, which equals the dimension of the row space, is called the rank of the matrix. The dimension of the nullspace is called the nullity. The first part of the fundamental theorem of linear algebra is that the nullspace has dimension n-r (i.e. rank + nullity = number of columns), and the left nullspace has dimension m-r, where r is the rank and m is the number of rows. The second part is that the column space is the orthogonal complement to the left nullspace and vice versa (i.e. all vectors that are orthogonal to the column space are in the left nullspace and vice versa) and the rowspace is the orthogonal complement to the nullspace and vice versa. So the column space and left nullspace are orthogonal complements in 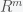 and the row space and nullspace are orthogonal complements in
and the row space and nullspace are orthogonal complements in  .
.
Now what does this have to do with solving linear systems and the Fredholm Alternative? Well consider again the system  . If b is in the column space of A, then a vector v can be found to satisfy this equation. If the column space is (i.e. r=m), then there is at least one solution v for any b. This would also imply that the left nullspace was empty so there could not be a solution to . So either there is a solution to or
. If b is in the column space of A, then a vector v can be found to satisfy this equation. If the column space is (i.e. r=m), then there is at least one solution v for any b. This would also imply that the left nullspace was empty so there could not be a solution to . So either there is a solution to or  . Now given that the left nullspace and column space are orthogonal complements, then it is also true that has a solution if and only if b is not in the left nullspace, i.e. .
. Now given that the left nullspace and column space are orthogonal complements, then it is also true that has a solution if and only if b is not in the left nullspace, i.e. .
So how is this applied to perturbation theory? I’ll sketch this out abstractly. Suppose we have a nonlinear equation  where the nonlinear operator can be written as
where the nonlinear operator can be written as 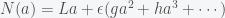 , where L is self-adjoint. Now consider an expansion for the solution
, where L is self-adjoint. Now consider an expansion for the solution 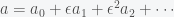 . Substituting this in and collecting order by order in
. Substituting this in and collecting order by order in  we obtain the equations
we obtain the equations
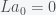



Now, the solvability condition for this system of linear equations is that  , which is in the left nullspace of L, must be orthogonal to
, which is in the left nullspace of L, must be orthogonal to  , for all n. This then gives a set of equations defined by
, for all n. This then gives a set of equations defined by  , which can be solved sequentially to derive the
, which can be solved sequentially to derive the 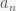 .
.

This would also imply that the left nullspace was empty so there could not be a solution to A^* w=0. So either there is a solution to A v=b or A^*w=0.
instead of empty you should maybe say no non-zero solutions.
But very good article.
LikeLike
hi. great explanation. but i have a doubt. In your explanation for the application in perturbation theory, why it the operator L assumed to be self-adjoint ?
LikeLike
Self-adjointness was just assumed to make the example simpler. It need not be in a real application.
LikeLike
Many thanks. Very helpful for idiots like me. :-) By the way, in the penultimate paragraph, there is a phrase: If the column space is R^m (i.e. r=m),….but isn’t this statement ALWAYS true? How does r=m follow from here?
LikeLike
Sagar: There is a difference between the dimension of the column space and the number of rows m. The rank could be smaller than the number of rows. However, if the nullity is zero then the rank is equal to the number of rows.
LikeLike
Oops, I should have said if the dimension of the left nullspace is zero then rank is the number of rows.
LikeLike
Reblogged this on varasdemate and commented:
I came across this theorem while reading basic algebraic properties of Petri Nets and I wanted to know how many of you are acquainted with it. Please post in the comments!
LikeLike
Hi! What its happened If we have we have a nonlinear equation with boundary conditions?
LikeLike
@harry Boundary conditions are fine but you must be careful to impose them correctly. The linear operator in perturbation theory may not have the same boundary conditions as the nonlinear operator, depending on how you define it.
LikeLiked by 1 person