It took me a very long time to develop an intuitive feel for information theory and Shannon entropy. In fact, it was only when I had to use it for an application that it finally fell together and made visceral sense. Now, I understand fully why people, especially in the neural coding field, are so focused on it. I also think that the concepts are actually very natural and highly useful in a wide variety of applications. I now think in terms of entropy and mutual information all the time.
Our specific application was to develop a scheme to find important amino acid positions in families of proteins called GPCRs, which I wrote about recently. Essentially, we have a matrix of letters from an alphabet of twenty letters. Each row of the matrix corresponds to a protein and each column of the matrix corresponds to a specific position on the protein. Each column is a vector of letters. Conserved columns are those which have very little variation in the letters and these positions are thought to be functionally important. They are also relatively easy to find.
What we were interested in was finding pairs of columns that are correlated in some way. For example, suppose whenever column 1 had the letter A (in a given row), column 2 was more likely to have the letter W, whereas when column 1 had the letter C, column 2 was less likely to have the letter P but more likely to have R and D. You can appreciate how hard it would be to spot these correlations visually. This is confounded by the fact that if the two columns have high variability then there will be random coincidences from time to time. So what we really want to know is the amount of correlation that exceeds randomness. As I show below, this is exactly what mutual information quantifies.
In essence, we are interested in the ratio between the joint probability distribution of the two columns 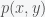

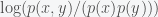
This now gives us the log of the odds ratio between correlated and independent letters but we want a single measure for the entire column. Hence, we then take the average of this log odds ratio, which gives us

where the sum is over all 400 possible pairs of letters. This measure is the mutual information between the two columns. When we were working on our project we basically arrived at this measure using the rationale above and then realized that we had simply derived the mutual information. One nice thing about mutual information is that you can use Jensen’s inequality to prove that it is never negative, i.e.

The mutual information is also the Kullback-Leibler divergence or distance between
Now we can also rewrite the mutual information as
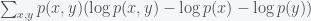


where 

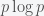
We can also see why the measure is called mutual information. If either one of the columns consisted of identical letters then the mutual information is zero since the entropy of a column of identical letters is zero and the entropy of the other column is equal to the joint entropy. This makes sense intuitively because if you were on the telephone and all you heard was A, A, A, A no matter what the other party said (or vice versa) then there would be no information transfered. If two columns are identical then the joint entropy is zero and the mutual information is twice the entropy of one column. This makes sense because the only limit on information transfered is the amount of information sent and that depends on how varied the message is. For example, if all you could ever send was the letter A then the other party would never have to answer the phone since they already know what you’ll say (If the column length was variable then the number of A’s would be information and that is quantified precisely by the entropy.) However, if your message was highly variable then a lot of information does get transfered each time you call and the other party is motivated to pick up the phone. So to have high mutual information you need to have high variability on both ends with high correlations. I think this is about the most intuitive notion of information you could have.

Neat explanation. I was happy to see that my “graphical proof” of Jensen’s inequality was still on Wikipedia, after nearly three years (!). But I was quickly saddened by the fact that I couldn’t quite re-understand it.
LikeLike
I think I can follow your graphical proof. Did you write the rest of the article as well?
LikeLike
Nah, only the graphical proof and the “Statistical physics” section. I think I also understand it now.
At the time I was writing about the Jarzynski equality (http://en.wikipedia.org/wiki/Jarzynski_equality), which is related to the 2nd law of thermodynamics by Jensen’s inequality. That article I’ve written pretty much from scratch, and hasn’t changed very much since then.
LikeLike
[…] by my former fellow Sarosh Fatakia. We applied our method using mutual information (see here and here) to a family of potassium channels known as TREK […]
LikeLike
very nice is a advice for cleaning
LikeLike